Содержание
IV. Проведение проверки сметной стоимости / КонсультантПлюс
IV. Проведение проверки сметной стоимости
18. Предметом проверки сметной стоимости является изучение и оценка расчетов, содержащихся в сметной документации, в целях установления их соответствия утвержденным сметным нормативам, сведения о которых включены в федеральный реестр сметных нормативов, физическим объемам работ, конструктивным, организационно-технологическим и другим решениям, предусмотренным проектной документацией, а также в целях установления непревышения сметной стоимости над укрупненным нормативом цены строительства.
(в ред. Постановлений Правительства РФ от 15.06.2017 N 712, от 13.12.2017 N 1541)
Абзац утратил силу. — Постановление Правительства РФ от 12.11.2016 N 1159.
При отсутствии укрупненных нормативов цены строительства для объектов, аналогичных по назначению, проектной мощности, природным и иным условиям территории, на которой планируется осуществлять строительство, также осуществляется изучение и оценка расчетов, содержащихся в сметной документации, на соответствие предполагаемой (предельной) стоимости строительства, рассчитанной на основе документально подтвержденных сведений о проектах-аналогах.
При принятии Правительством Российской Федерации решения о неприменении критерия экономической эффективности проектной документации в части сметной стоимости строительства объекта капитального строительства, которая не должна превышать предполагаемую (предельную) стоимость строительства, определенную с применением укрупненных нормативов цены строительства или с использованием документально подтвержденной органами и организациями, уполномоченными на проведение государственной экспертизы, сметной стоимости объектов, аналогичных по назначению, проектной мощности, природным и иным условиям территории, на которой планируется осуществлять строительство, изучение и оценка расчетов, содержащихся в сметной документации, в целях установления их соответствия укрупненным нормативам цены строительства или предполагаемой (предельной) стоимости строительства, рассчитанной на основе подтвержденной органами государственной экспертизы сметной стоимости проектов-аналогов, не производится.
В случаях, если разработка проектной документации не требуется, проводится оценка соответствия указанных в абзаце первом настоящего пункта расчетов физическим объемам работ, включенным в ведомость объемов работ или акт технического осмотра объекта капитального строительства и дефектную ведомость при проведении проверки сметной стоимости капитального ремонта.
19. Проверка сметной стоимости проводится в предусмотренный договором срок, который не может быть более 30 рабочих дней. В случае если проверка сметной стоимости проводится одновременно с проведением государственной экспертизы проектной документации и результатов инженерных изысканий или подготовкой заключения о модификации проектной документации, такая проверка осуществляется в пределах срока проведения государственной экспертизы или подготовки заключения о модификации проектной документации.
20. При проведении проверки сметной стоимости внесение изменений в сметную документацию может осуществляться в сроки и в порядке, которые предусмотрены договором. При этом срок проведения проверки сметной стоимости может быть продлен на основании договора или дополнительного соглашения к нему, но не более чем на 30 рабочих дней.
20(1). Срок проведения проверки сметной стоимости капитального ремонта объекта капитального строительства, указанный в пункте 19 настоящего Положения, может быть сокращен, но не менее чем до 10 рабочих дней, в случае наличия соответствующего поручения (решения) Президента Российской Федерации, Правительства Российской Федерации или высшего должностного лица субъекта Российской Федерации.
21. В случае если при проведении проверки сметной стоимости выявляются недостатки (отсутствие либо неполнота сведений, описаний, расчетов, чертежей, схем и т.п.), не позволяющие сделать выводы о достоверности или недостоверности представленных расчетов, заявителю в течение 3 рабочих дней направляется уведомление о выявленных недостатках и при необходимости устанавливается срок их устранения.
22. Организация по проведению проверки оформляет заключение о недостоверности определения сметной стоимости строительства, реконструкции, капитального ремонта объекта капитального строительства, работ по сохранению объекта культурного наследия, если:
(в ред. Постановлений Правительства РФ от 12.11.2016 N 1159, от 13.12.2017 N 1541)
а) выявленные недостатки невозможно устранить в процессе проведения проверки сметной стоимости или заявитель в установленный срок их не устранил;
б) расчеты, содержащиеся в сметной документации, произведены не в соответствии с утвержденными сметными нормативами, сведения о которых включены в федеральный реестр сметных нормативов;
в) в сметной документации выявлены ошибки, связанные с неправильностью и (или) необоснованностью использованных в расчетах физических объемов работ, конструктивных, организационно-технологических и других решений, принятых в проектной документации.
23. При отсутствии сметных нормативов, подлежащих применению при расчете сметной стоимости строительства, заинтересованное лицо вправе подготовить необходимые сметные нормативы и представить их в Министерство строительства и жилищно-коммунального хозяйства Российской Федерации для включения в установленном порядке в федеральный реестр сметных нормативов.
(в ред. Постановлений Правительства РФ от 23.09.2013 N 840, от 26.03.2014 N 230)
Как изменится порядок проверки достоверности сметной стоимости
На портале проектов нормативных правовых актов опубликован проект Постановления Правительства РФ «О внесении изменений в Положение об организации и проведении государственной экспертизы проектной документации и результатов инженерных изысканий».
Фото: www.obrazilla.ru
Согласно ч. 3.9 ст.49 ГрК РФ, оценка соответствия изменений, внесенных в проектную документацию (ПД), получившую положительное заключение экспертизы, по решению застройщика или технического заказчика может осуществляться в форме экспертного сопровождения органами, проводившими экспертизу ПД, которые подтверждают соответствие внесенных в ПД изменений.
3.9 ст.49 ГрК РФ, оценка соответствия изменений, внесенных в проектную документацию (ПД), получившую положительное заключение экспертизы, по решению застройщика или технического заказчика может осуществляться в форме экспертного сопровождения органами, проводившими экспертизу ПД, которые подтверждают соответствие внесенных в ПД изменений.
Проектом Постановления уточняется, что в случае, если в результате изменений, внесенных в ПД в ходе экспертного сопровождения, сметная стоимость строительства / реконструкции объекта капитального строительства изменилась и не соответствует той, что установлена в решении о предоставлении бюджетных ассигнований, для проведения государственной экспертизы изменений, внесенных в ПД в ходе экспертного сопровождения, предоставляется смета на строительство, реконструкцию, разработанная на технологически законченный конструктивный элемент здания (сооружения), включающий необходимые для его возведения (устройства) комплексы работ, подвергшиеся изменениям.
Фото: www.c.pxhere.com
При этом устанавливается, что для проведения государственной экспертизы по результатам экспертного сопровождения в рамках срока действия договора об экспертном сопровождении документы могут представляться неограниченное количество раз.
Публичное обсуждение проекта документа продлится до 19 мая 2021 года.
Фото: www.dpo-ilm.ru
Другие публикации по теме:
Актуальные индексы сметной стоимости: новые изменения
Утверждены изменения индексов сметной стоимости в I квартале 2021 года
Новые изменения индексов сметной стоимости в I квартале 2021 года
Методика определения сметной стоимости подготовки проектной документации, содержащей материалы в форме информационной модели
Утверждены нормативы сметной прибыли по видам работ
Минстрой уточнил рекомендуемые индексы изменения сметной стоимости на I квартал 2021 года
Как осуществляется оценка проектной документации на соответствие санэпидтребованиям
Как изменится положение о проведении экологической экспертизы
Скорректированный перечень документов для проведения госэкспертизы
Дополнен перечень направлений деятельности экспертов, осуществляющих экспертизу проектной документации и результатов инженерных изысканий
Порядок применения новой Методики определения сметной стоимости
Как скорректируют методику расчета индексов изменения сметной стоимости
Утверждена новая методика определения сметной стоимости
Минстрой планирует создать реестр документов в области инженерных изысканий, проектирования, строительства и сноса: комментарий эксперта
Как проводится экспертное сопровождение
Минстрой изменил порядок осуществления экспертного сопровождения строительства: комментарий специалиста
Нюансы экспертного сопровождения проекта: комментарий специалиста
Проверка достоверности определения сметной стоимости: взгляд экспертов Главгосэкспертизы России
О последних изменениях законодательства, а также о порядке проведения государственной экспертизы проектной документации и проверки достоверности определения сметной стоимости строительства рассказали представители Главгосэкспертизы России Елена Бачинская и Вадим Полянский в рамках семинара «Ценообразование и сметное нормирование в строительстве. Актуальные вопросы на современном этапе».
Актуальные вопросы на современном этапе».
Заместитель начальника сметного отдела Управления проверки сметной документации и экспертизы проектов организации строительства Елена Бачинская обратила внимание участников семинара на то, что проверка достоверности определения сметной стоимости осуществляется в отношении объектов капитального строительства, финансируемых с привлечением средств федерального бюджета, независимо от необходимости получения разрешения на строительство, обязательности подготовки проектной документации и государственной экспертизы проектной документации и результатов инженерных изысканий.
Проверка может осуществляться одновременно с проведением государственной экспертизы проектной документации и результатов инженерных изысканий, после нее, если экспертизу и проверку проводят разные организации, и без проведения государственной экспертизы, если подготовка проектной документации и ее экспертиза не являются обязательными, заметила Елена Бачинская.
Кроме того, эксперт напомнила, что внесение изменений в сметную документацию даже при проведении проверки сметной стоимости возможно — в порядке, предусмотренном договором. При этом срок проведения проверки может быть продлен, но не более чем на 30 рабочих дней, — условия продления оговариваются в договоре или дополнительном соглашении к нему.
Сегодня Главгосэкспертиза России проводит экспертизу проектной документации и результатов инженерных изысканий в электронном виде – это обязательно для проектов, финансируемых полностью или частично с привлечением средств федерального бюджета. Однако с 1 января 2017 года прохождение государственной экспертизы в электронном виде будет обязательно для всех проектов вне зависимости от источников финансирования. Главгосэкспертиза России технически готова к запуску нового сервиса – проведению проверки достоверности определения сметной стоимости в электронном виде. Как только будет выпущен соответствующий нормативно-правовой акт, эта услуга будет открыта для пользователей. «Пока сметная документация должна представляться на бумажном носителе и в электронном виде, в установленном формате и заверенная электронными подписями», — сообщила Елена Бачинская.
Начальник отдела методологии Управления сопровождения проектов Вадим Полянский, разъясняя последние новеллы законодательства, отметил, что раньше проверка была обязательна только в отношении сметной стоимости строительства, реконструкции объектов капитального строительства, финансирование которых планировалось осуществлять с привлечением средств федерального бюджета. Однако в соответствии с последними изменениями Градостроительного кодекса Российской Федерации и некоторых нормативных актов Правительства Российской Федерации в настоящее время проверке подлежит сметная стоимость не только строительства и реконструкции, но и капитального ремонта, финансирование которых планируется осуществлять полностью или частично за счет средств бюджетов бюджетной системы Российской Федерации.
«Кроме того, теперь проверка обязательна и для тех проектов, строительство, реконструкцию и капитальный ремонт которых финансируют юридические лица, созданные Российской Федерацией, субъектами Российской Федерации и муниципальными образованиями, а также юридические лица, доля Российской Федерации, субъектов Российской Федерации и муниципальных образований в уставных (складочных) капиталах которых составляет более 50%», — сказал Вадим Полянский.
При этом проведение государственной экспертизы и проверки достоверности определения сметной стоимости строительства, реконструкции и капитального ремонта, финансируемых за счет средств указанных юридических лиц, отнесено законодателем к полномочиям Главгосэкспертизы России. Эти работы могут осуществляться также и в государственных экспертных организациях субъектов Российской Федерации при условии, что объекты экспертизы не относятся к указанным в пункте 5.1 части 1 статьи 6 Градостроительного кодекса.
Одним из важных нововведений в области проведения проверки сметной стоимости, подчеркнул Вадим Полянский, является установление общих правил выполнения оценки сметной стоимости для всех объектов, предусмотренных Положением № 427, независимо от источника их финансирования. «Если проектная документация по объектам, финансируемым за счет средств региональных, местных бюджетов либо средств юридических лиц субъектов Российской Федерации и муниципальных образований, подлежит государственной экспертизе на федеральном уровне, то проверка сметной стоимости строительства, реконструкции таких объектов также проводится в Главгосэкспертизе России одновременно с экспертизой проектной документации», — заметил начальник отдела методологии.
В ходе своего выступления Вадим Полянский обсудил со слушателями преобразование института типового проектирования, особенности проведения повторной экспертизы, сроки проведения экспертизы и их продление, создание Единого государственного реестра заключений экспертизы проектной документации объектов капитального строительства и другие актуальные вопросы проведения государственной экспертизы проектной документации и результатов инженерных изысканий.
Семинар «Ценообразование и сметное нормирование в строительстве. Актуальные вопросы на современном этапе» был проведен ФАУ ФЦЦС при участии Главгосэкспертизы России.
Проверка достоверности определения сметной стоимости в электронной форме
В связи с принятием постановления Правительства Российской Федерации от 23.01.2017 № 51
с 3 февраля 2017 года,документы для проведения проверки достоверности определения сметной стоимости объектов капитального строительства, финансирование которых осуществляется с привлечением средств бюджетов бюджетной системы Российской Федерации, средств юридических лиц, созданных Российской Федерацией, субъектами Российской Федерации, муниципальными образованиями, юридических лиц, доля Российской Федерации, субъектов Российской Федерации, муниципальных образований в уставных (складочных) капиталах которых составляет более 50 процентов, должны представляться в форме электронных документов.
Постановление Правительства РФ от 18 мая 2009 г. N 427
Требования к формату электронных документов перечислены в Приказе Минстроя России от 12.05.2017 № 783/пр
Для документов, содержащих сводки затрат, сводного сметного расчета стоимости строительства, объектных сметных расчетов (смет), локальных сметных расчетов (смет), сметных расчетов на отдельные виды затрат допустимые форматы электронного документа, только — xml и xls, xlsx, ods (Microsoft Excel и Open Office)
Перечень документов, представляемых заявителем для проведения проверки достоверности определения сметной стоимости объектов капитального строительства, финансирование строительства которых планируется осуществлять с привлечением средств федерального бюджета.
Настройка рабочего места для работы в «Личном кабинете»
Инструкция по работе в «Личном кабинете заказчика»
Для получения государственной услуги Заявителю потребуется:
- доступ в интернет
Последовательность предоставления услуги в электронной форме:
– авторизация в «Личном кабинете заказчика» при помощи учетной записи портала государственных услуг
– заполнение заявления в электронной форме
– загрузка документации в электронной форме
– заключение договора в электронной форме
– рассмотрение, выдача писем-уведомлений о выявленных недостатках в проектной документации, загрузка доработанной документации в личный кабинет
– оформление результатов экспертизы
– передача заключения в электронной форме
По вопросам проведения экспертизы,обращайтесь в Системный отдел по телефону 8(4722)31-82-25,
По технической поддержке 8(4722)31-81-88 Владимир
Проверка достоверности определения сметной стоимости
Проверка достоверности определения сметной стоимости
Наша компания, из числа своих многочисленных сметных услуг, готова предложить Вам — профессиональное проведение проверки достоверности определения сметной стоимости.
(Обращаем внимание: выдается только частное заключение аттестованного инженера-сметчика. Для получения заключения от экспертной организации, Вам необходимо обратиться в специализированную аккредитованную организацию)
Когда необходима такая услуга?
Значение экспертизы сметы нельзя недооценивать. В современных условиях конкуренции на строительном рынке, на фоне постоянного изменения рыночной стоимости материалов и ресурсов проверка достоверности определения сметной стоимости – уже не просто технический необходимый процесс, но и один их важнейших факторов экономического значения и снижения рисков компании. От грамотных и точных расчетов сметчика зависит вложение материальных средств Компании и эффективность их дальнейшего использования.
Экспертиза сметы может проводиться:
- Параллельно с инженерными изысканиями и проверкой, государственных органов строительного надзора;
- По окончании строительно-монтажных работ, вне зависимости от источника финансирования объекта;
- По окончании указанных выше работ при собственном финансировании объектов, которые подлежат обязательной проверке государственными органами;
- Без государственной проверки, если таковая не требуется.


Состав работ при проверке достоверности определения сметной стоимости.
Все мероприятия, входящие в состав процесса проверки достоверности определения сметной стоимости, можно разделить на несколько этапов:
1. Оценка полноты комплекта разработанной сметной документации;
2. Оценка сметной стоимости строительных работ;
3. Оценка соответствия действующим нормам расчетов и используемых при этом нормативов.
Любая проверка достоверности определения сметной стоимости – это тщательная проработка документации, включающая: контроль над правильностью использования в расчете нормативов средней стоимости материалов, норм расхода, затрат на работу техники и персонала, планируемых для выполнения строительных мероприятий.
После выполнения проверки достоверности определения сметной стоимости заказчик получает мотивированное заключение. В котором, с указанием на примененные нормативные документы, показываются позиции с существенными завышениями/занижениями с указанием конкретной суммы завышения и возможными причинами.
Что дает заказчику проверка достоверности определения сметной стоимости от компании Эксперты-24? В первую очередь – стопроцентную уверенность в правильной оценке стоимости строительного объекта и гарантию последующего качественного выполнения работ подрядчиком.
Звоните по телефону в Москве 8 (985) 780-70-61. Пишите на электронную почту [email protected]
Порядок и цели проверки сметы на достоверность . Проверка сметной документации, проверка достоверности определения сметной стоимости. Экспертиза смет
Для того чтобы определить сметную стоимость строительства определенного здания или сооружения, необходимо в обязательном порядке составить и подготовить сметные документы.
Как правило, в сметную документацию входят локальная смета, локальные сметные расчеты, объектные сметы, объектные сметные расчеты, а также сметные расчеты на определенные типы расходов, сводные сметные расчеты цены на строительство, сводки затрат и другие составляющие.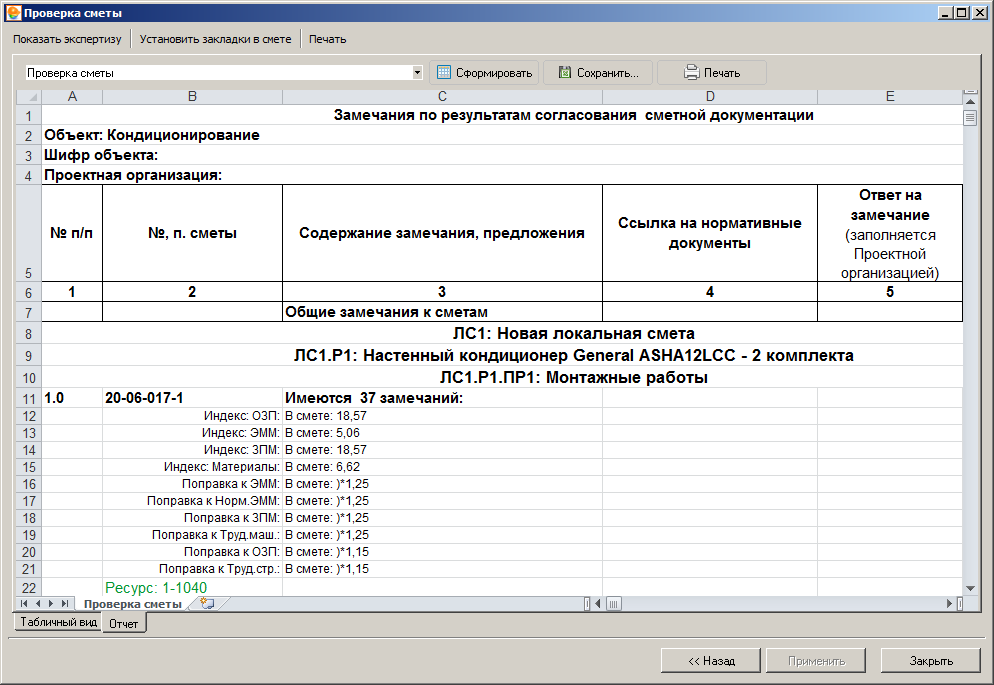
Во время процесса работы над составлением смет эксперты используют ресурсный, базисно-индексный, ресурсно-индексный метод для установления стоимости строительства в сметах.
Анализ и расчет сметных документов выполняется, прежде всего, в экономических целях. Однако все подобные вычисления влияют также на контроль качества строительства. Весь итог, эффективность, надежность и качество всего строительного процесса также зависят от изначального верного составления сметных документов.
Все инвесторы заинтересованы как в рентабельности будущего проекта, так и в прекрасном его техническое выполнении. Никто не хочет, чтобы его объект стал провальным. Доверить проверку сметных документов принято независимым экспертным компаниям. В них трудятся настоящие профи своего дела, за плечами у которых тысячи проверенных сметных документов.
Если сметные документы проверить правильно, с использованием всех необходимых технических средств для проверки, весь контроль над строительными работами будет значительно улучшен сразу же.
С помощью проверенной и отредактированной сметной документации, отношения между заказчиком строительства и застройщиком на любом этапе выполнения работ будут прописаны в сметных документах.
Смета также позволяет заказчику понять, насколько строительство уже завершено, сколько денег потрачено, а сколько еще нужно для того, чтобы вовремя и технически грамотно завершить все работы на объекте.
Если проверить сметную документацию на стадии реализации строительства, можно в самом процессе работы сделать замену дорогих материалов более выгодными по цене.
Таким образом, подробное составление смет, а также их анализ и проверка специалистами на любом этапе строительства позволит сделать процесс управления возведением всего объекта максимально гибким, понятным и эффективным.
Проведение проверки достоверности определения сметной стоимости
17.01.2020 вступило в силу постановление Правительства Российской Федерации от 31.12.2019 № 1948 «О внесении изменений в некоторые акты Правительства Российской Федерации и признании утратившими силу некоторых актов и отдельных положений некоторых актов Правительства Российской Федерации».
В частности, указанным постановлением внесены изменения в постановление Правительства Российской Федерации от 05.03.2007 № 145 «О порядке организации и проведения государственной экспертизы проектной документации и результатов инженерных изысканий», признано утратившим силу постановление Правительства Российской Федерации от 18 мая 2009 № 427.
С 17.01.2020 проверка достоверности определения сметной стоимости является предметом государственной экспертизы проектной документации (предусмотрена пунктом 2 части 5 статьи 49 Градостроительного кодекса Российской Федерации) и оформляется единым заключением государственной экспертизы проектной документации.
Проверка сметной документации
Для объектов, не требующих проведения проверки достоверности определения сметной стоимости, может проводиться проверка сметной стоимости на основании Приказа начальника ГАУ «Леноблгосэкспертиза» от 25 ноября 2013 года N 61.
Проверка сметной документации проводится в случае проведения текущего, аварийного ремонта, ремонта или технического перевооружения (если такое перевооружение не связано со строительством или реконструкцией) объектов капитального строительства или их частей, финансирование которых осуществляется (планируется осуществлять) полностью или частично за счет средств областного бюджета Ленинградской области, средств бюджетов муниципальных образований Ленинградской области, а также в случае строительства, реконструкции, текущего, аварийного, капитального ремонта, ремонта или технического перевооружения объектов капитального строительства или их частей, финансирование которых осуществляется за счет средств внебюджетных источников.
Определение надежности теста: 4 метода
Обычно используются четыре процедуры для вычисления коэффициента надежности (иногда называемого самокорреляцией) теста. Это: 1. Повторный тест (повторение) 2. Альтернативные или параллельные формы 3. Техника разделения полов 4. Рациональная эквивалентность.
1. Метод повторного тестирования:
Для оценки надежности с помощью метода повторного тестирования один и тот же тест проводится дважды с одной и той же группой учеников с заданным временным интервалом между двумя введениями теста.
Полученные результаты тестов коррелированы, и этот коэффициент корреляции обеспечивает меру стабильности, то есть показывает, насколько стабильны результаты теста в течение определенного периода времени. Так что это иначе известно как мера стабильности.
Оценка надежности в этом случае зависит от продолжительности временного интервала, разрешенного между двумя администрациями. Метод корреляции моментов продукта — важный метод оценки надежности двух наборов оценок.
Таким образом, высокая корреляция между двумя наборами оценок указывает на надежность теста. Значит, это показывает, что баллы, полученные при первом введении, похожи на баллы, полученные при втором проведении того же теста.
В этом методе важную роль играет временной интервал. Если оно слишком мало, скажем, день или два, на согласованность результатов будет влиять эффект переноса, то есть ученики запомнят некоторые результаты от первого приема ко второму.
Если временной интервал длинный, например год, на результаты будет влиять не только неравенство процедур и условий тестирования, но также и фактические изменения в учениках за этот период времени.
Промежуток времени проведения ретеста не должен превышать шести месяцев. Двухнедельный интервал повторного тестирования (2 недели) дает точный показатель надежности.
Преимущества :
Для оценки коэффициента надежности обычно используется метод самокорреляции или тест-ретест. Стоит удобно использовать в разных ситуациях. Тест адекватной продолжительности можно использовать после многодневного интервала между последовательными тестами.
Стоит удобно использовать в разных ситуациях. Тест адекватной продолжительности можно использовать после многодневного интервала между последовательными тестами.
Недостатки :
1. Если тест повторяется немедленно, многие испытуемые вспомнят свои первые ответы и потратят время на новый материал, таким образом, стремясь повысить свои баллы, иногда значительно.
2. Помимо немедленного эффекта памяти, практика и уверенность, вызванные знакомством с материалом, почти наверняка повлияют на результаты при повторной сдаче теста.
3. Полученный таким образом показатель надежности менее точен.
4. Если интервал между тестами достаточно большой (более шести месяцев), фактор роста и зрелости будет влиять на оценки и имеет тенденцию к снижению индекса надежности.
5. Если тест повторяется сразу или после небольшого промежутка времени, может существовать вероятность эффекта переноса / эффекта переноса / эффекта памяти / практики.
6. Повторное повторение одного и того же теста в одной и той же группе второй раз делает студентов незаинтересованными, и поэтому они не хотят принимать участие полностью.
7. Иногда единообразие не соблюдается, что также влияет на результаты тестов.
8. Вероятность обсуждения нескольких вопросов после первого введения, которые могут увеличить баллы при втором введении, влияя на надежность.
2. Метод альтернативной или параллельной формы:
Оценка надежности с помощью метода эквивалентной формы включает использование двух различных, но эквивалентных форм теста. Надежность параллельной формы также известна как надежность альтернативной формы или эквивалентная надежность формы или сопоставимая надежность формы.
В этом методе используются две параллельные или эквивалентные формы теста. Под параллельными формами мы подразумеваем, что формы эквивалентны по содержанию, целям, формату, уровню сложности и отличительной ценности заданий, длине теста и т. Д..
Д..
Параллельные тесты имеют одинаковые средние баллы, дисперсию и взаимосвязь между заданиями. То есть две параллельные формы должны быть однородными или похожими во всех отношениях, но не дублировать тестовые задания. Пусть двумя формами будут Форма A и Форма B.
Коэффициент надежности можно рассматривать как коэффициент корреляции между оценками по двум эквивалентным формам теста. Две эквивалентные формы должны быть, возможно, схожими по содержанию, степени, проверяемым умственным процессам, уровню сложности и другим аспектам.
Одна форма теста проводится с учащимися, и сразу после завершения другой формы теста предоставляется той же группе. Полученные таким образом оценки коррелируют, что дает оценку надежности.Таким образом, найденная надежность называется коэффициентом эквивалентности.
Гулликсен 1950: определяет параллельные тесты как тесты, имеющие равные средние значения, равную дисперсию и равные взаимосвязи между ними.
Гилфорд: Метод альтернативной формы указывает как на эквивалентность содержания, так и на стабильность работы.
Преимущества :
Данная процедура имеет определенные преимущества перед методом повторного тестирования:
1. Здесь тот же тест не повторяется.
2. Память, практика, эффекты переноса и факторы вспоминания сведены к минимуму и не влияют на оценки.
3. Коэффициент надежности, полученный этим методом, является мерой как временной стабильности, так и последовательности ответа на различные образцы заданий или формы тестирования. Таким образом, этот метод сочетает в себе два типа надежности.
4. Полезно для проверки достоверности достижений.
5. Этот метод является одним из подходящих методов определения достоверности учебных и психологических тестов.
Ограничения :
1. Трудно иметь две параллельные формы теста. В определенных ситуациях (например, в Роршахе) это практически невозможно.
2. Если тесты не совсем равны с точки зрения сложности содержания и длины, сравнение двух наборов баллов, полученных в результате этих тестов, может привести к ошибочным решениям.
3. Практические и переходящие факторы нельзя полностью контролировать.
4. Более того, одновременное ведение двух форм вызывает скуку.Вот почему люди предпочитают такие методы, при которых требуется только одно проведение теста.
5. Условия тестирования при приеме Формы B могут не совпадать. Кроме того, яички не могут находиться в одинаковом физическом, психическом или эмоциональном состоянии во время введения.
6. Результаты второй формы теста в целом высокие.
Хотя сложные, тщательно и осторожно построенные параллельные формы дадут нам достаточно удовлетворительную меру надежности.Для хорошо выполненных стандартизированных тестов метод параллельной формы обычно является наиболее удовлетворительным способом определения надежности.
3. Метод разделения на две части или метод разделения на части:
Метод разделения половин является улучшением по сравнению с двумя предыдущими методами и включает в себя как характеристики стабильности, так и эквивалентности. Обсуждаемые выше два метода оценки надежности иногда кажутся сложными.
Обсуждаемые выше два метода оценки надежности иногда кажутся сложными.
Может оказаться невозможным выполнить один и тот же тест дважды и получить эквивалентные формы теста.Следовательно, для преодоления этих трудностей и уменьшения эффекта памяти, а также для экономии теста желательно оценить надежность путем однократного проведения теста.
В этом методе тест проводится один раз на образце, и это наиболее подходящий метод для однородных тестов. Этот метод обеспечивает внутреннюю согласованность результатов теста.
Все элементы теста обычно располагаются в порядке возрастания сложности и проводятся один раз на выборку.После проведения теста он делится на две сопоставимые или похожие или равные части или половины.
Оценки распределяются или делятся на два набора, полученных отдельно из нечетного количества элементов и четного количества элементов. Например, проводится тест из 100 пунктов.
Очки отдельных участников на основе 50 пунктов нечетных чисел, таких как 1, 3, 5, . . 99 и оценки, основанные на четных числах 2, 4, 6… 10, расположены отдельно. В части «A» присваиваются элементы с нечетным номером, а в части «B» должно быть четное количество элементов.
. 99 и оценки, основанные на четных числах 2, 4, 6… 10, расположены отдельно. В части «A» присваиваются элементы с нечетным номером, а в части «B» должно быть четное количество элементов.
После получения двух баллов по нечетному и четному количеству тестовых заданий вычисляется коэффициент корреляции. На самом деле это соотношение между двумя равными половинами баллов, полученных за один присест. Для оценки надежности используется формула пророчества Спирмена-Брауна.
Формула Спирмена-Брауна дается по:
, где r 11 = надежность всего теста.
r 11/22 = коэффициент корреляции между двумя полутестами.
Пример 1:
Тест содержит 100 элементов. Все эти предметы расположены в порядке сложности от первого до сотого. Студенты отвечают на тест, и тест оценивается.
Баллы выставляются учащимися по нечетному количеству заданий, а четное количество заданий суммируется отдельно. Коэффициент корреляции между этими двумя наборами оценок составляет 0,8.
Коэффициент корреляции между этими двумя наборами оценок составляет 0,8.
Надежность всего теста (или)
При использовании этой формулы следует иметь в виду, что дисперсия четных и нечетных половин должна быть одинаковой, т.е.е.
Если это невозможно, можно использовать формулы Фланагана и Рулона. Эти формулы более простые и не требуют вычисления коэффициента корреляции между двумя половинами.
Преимущества :
1. Здесь мы не повторяем тест или не используем его параллельную форму, поэтому тестируемый не тестируется дважды. Таким образом, эффекта переноса или эффекта практики здесь нет.
2.В этом методе минимизируются колебания способностей человека из-за внешних или физических условий.
3. За счет однократного проведения теста повседневные функции и проблемы не мешают.
4. Устранена трудность построения параллельных форм теста.
Ограничения:
1. Тест можно разделить на две равные половины разными способами, и коэффициент корреляции в каждом случае может быть разным.
Тест можно разделить на две равные половины разными способами, и коэффициент корреляции в каждом случае может быть разным.
2. Этот метод нельзя использовать для оценки надежности скоростных тестов.
3. Поскольку lest применяется один раз, случайные ошибки могут одинаково повлиять на результаты двух половин и, таким образом, сделать коэффициент надежности слишком высоким.
4. Этот метод нельзя использовать в испытаниях мощности и гетерогенных испытаниях.
Несмотря на все эти ограничения, метод разделения половин считается лучшим из всех методов измерения надежности испытаний, так как данные для определения надежности получаются время от времени и, таким образом, сокращаются время, трудозатраты и трудности, связанные с повторное или повторное введение.
4. Метод рациональной эквивалентности:
Этот метод также известен как «надежность Кудера-Ричардсона» или «согласованность между элементами». Это метод, основанный на однократном применении. Он основан на единообразии ответов на все вопросы.
Он основан на единообразии ответов на все вопросы.
Самый распространенный способ найти согласованность между элементами — использовать формулу, разработанную Кудером и Ричардсоном (1937). Этот метод позволяет вычислить взаимную корреляцию элементов теста и корреляцию каждого элемента со всеми элементами теста.Дж. Кронбах назвал это коэффициентом внутренней согласованности.
В этом методе предполагается, что все задания имеют одинаковое или равное значение сложности, корреляция между заданиями одинакова, все задания измеряют, по существу, одинаковые способности, и тест является однородным по своей природе.
Как и метод разделения половин, этот метод также обеспечивает меру внутренней согласованности.
Самая популярная формула — это формула Кудера-Ричардсона, то есть KR-21, которая приведена ниже:
q = — p
p = 1 — q
Пример поможет нам вычислить p и q.
Пример 2:
60 учеников явились тестом, из них 40 учеников правильно ответили на тот или иной пункт теста.
р = 40/60 = 2/3
Это означает, что y часть студентов правильно ответили на один конкретный элемент теста. 20 студентов неправильно ответили на этот вопрос.
Таким образом, q = 20/60 или 1 — 40/60
Для каждого элемента мы должны определить значение p и q, затем pq суммируется по всем элементам, чтобы получить ∑pq.Умножьте p и q для каждого элемента и суммируйте для всех элементов. Это дает ∑pq.
Преимущества :
1. Этот коэффициент показывает, насколько внутренне согласованными или однородными являются элементы тестов.
2. Рациональная эквивалентность превосходит метод разделения половин в некоторых теоретических аспектах, но фактическая разница в коэффициентах надежности, обнаруженная двумя методами, часто незначительна.
3. Метод разделения половин просто измеряет эквивалентность, а метод рациональной эквивалентности измеряет как эквивалентность, так и однородность.
4. Экономичный метод, так как тест проводится однократно.
5. Он не требует проведения двух эквивалентных форм тестов и не требует разделения тестов на две равные половины.
Ограничения :
1. Коэффициент, полученный этим методом, обычно несколько меньше, чем коэффициенты, полученные другими методами.
2. Если элементы тестов не очень однородны, этот метод даст более низкий коэффициент надежности.
3. Метод Кудера-Ричардсона и метод разделения половин не подходят для испытания скорости.
4. Разные формулы KR дают разные показатели надежности.
(PDF) Процессы и процедуры оценки надежности и точности баллов
ИЗМЕРЕНИЕ И ОЦЕНКА В КОНСУЛЬТАЦИИ И РАЗРАБОТКЕ 259
на практике этого не делает. Результирующий KR – 20 = 0,964 интерпретируется как 96,4% истинной дисперсии
баллов (то есть согласованности) и 3,6% дисперсии ошибки (т.е., несогласованность: неоднородность набора предметов).
Надежность повторного тестирования
Надежность повторного тестирования (rtt; то есть временная стабильность) означает согласованность ответов на одну и ту же оценку —
, примененную к одной и той же группе людей в двух разных случаях. Это коэффициент стабильности
Это коэффициент стабильности
с течением времени, при этом дисперсия ошибок обусловлена либо колебаниями во времени оцениваемой конструкции
(например, изменения в состоянии испытуемых), либо внутренними или внешними факторами. условия тестирования (e.г.,
отвлекаемость, угадывание, время администрирования).
Чтобы проиллюстрировать концепцию надежности теста-повторного тестирования, снова рассмотрим базу данных, представленную в Таблице 1. Используя
SPSS24, баллы в столбце T1 были коррелированы с баллами в столбце T2 (для времени 1 и времени 2,
соответственно. ), чтобы отразить результаты одного и того же теста, проведенного учителем с интервалом в 1 месяц. Полученная корреляция
составила rtt = 0,968, что интерпретируется как истинная дисперсия 96,8% и 3.2% дисперсия ошибки, в
в этом случае из-за нестабильности во времени либо из-за обстоятельств тестирования, либо из-за изменений условий
испытуемых в момент 1 или момент 2. Точная интерпретация коэффициента надежности повторного тестирования составляет
Точная интерпретация коэффициента надежности повторного тестирования составляет
в зависимости от временного интервала между двумя администрациями и характера конструкции —
измеряется. Поскольку оценки при консультировании часто используются для отслеживания терапевтического прогресса клиентов в лечении
, надежность повторного тестирования может дать полезную информацию о влиянии повторного проведения теста
на оценки клиентов.Однако соответствие временного интервала между тестами и повторными тестами, основанное на измеряемой конструкции,
является решающим, поскольку сама конструкция может колебаться в разные периоды времени, при этом
систематически изменяются на характеристике, измеряемой между введениями. Например, если измеряемая конструкция
изменяется во времени (например, депрессия), длительный интервал времени между двумя введениями
может привести к различиям из-за биологического созревания, когнитивного развития или изменений опыта
или настроения . С другой стороны, повторное администрирование в течение короткого интервала времени (например, нескольких дней) может привести к эффекту переноса
С другой стороны, повторное администрирование в течение короткого интервала времени (например, нескольких дней) может привести к эффекту переноса
из-за клиентской памяти или практики.
Чтобы еще больше проиллюстрировать это, клиент с диагнозом депрессия, которому был назначен опросник депрессии Beck
— второе издание (BDI – II; Beck, Steer, & Brown, 1996), мог бы получить более низкий балл
, если второй введение BDI – II произошло через 6 месяцев, независимо от эффективности лечения.Сообщаемые оценки надежности теста – повторного тестирования для данной оценки зависят от выборки, и можно ожидать, что только
будут сопоставимы за аналогичные периоды оценки. Снова используя пример BDI – II,
, первоначально сообщенная (Beck et al., 1996), оценка rtt составила 0,93 с клиническим образцом, повторно протестированным только через 1 неделю.
не может применяться к 6-недельному периоду оценки. Действительно, недавний психометрический синтез
с BDI-II сообщил о существенно более низких оценках надежности повторных тестов для клинических образцов за период
в 6 недель (rtt =. 68; Эрфорд, Джонсон и Бардхоши, 2016). Исследователи всегда должны указывать интервал времени
68; Эрфорд, Джонсон и Бардхоши, 2016). Исследователи всегда должны указывать интервал времени
между первой и второй администрациями, учитывая его влияние на оценку надежности.
Надежность альтернативных форм (надежность эквивалентных форм)
Потенциальное влияние практики на надежность теста-повторного тестирования можно уменьшить, если экзаменуемые
будут брать две эквивалентные версии данной оценки с разными но эквивалентная версия используется в каждом периоде администрирования
.Меры, которые оценивают одну и ту же конструкцию, а также схожи по наблюдаемой оценке
средних, дисперсий и корреляций с другими оценками, называются альтернативными формами (или эквивалентными
альтернативными формами). Некоторыми примерами являются формы A, B и C теста Woodcock – Johnson IV: Tests of Achievement-
ment (Schrank, McGrew, & Mather, 2014) и синие и коричневые формы теста Wide-Range Achievement
( WRAT – 4; Wilkinson & Robertson, 2006). Поскольку эти оценки измеряют достижения, создание альтернативных форм проще из-за большего выбора тестовых заданий.Альтернативные формы психологических конструктов
Поскольку эти оценки измеряют достижения, создание альтернативных форм проще из-за большего выбора тестовых заданий.Альтернативные формы психологических конструктов
(например, самооценка) гораздо менее распространены, что делает оценки надежности альтернативных форм менее применимыми. Обратите внимание, что полная и краткая версии экзамена не являются эквивалентными формами.
Чтобы проиллюстрировать концепцию надежности альтернативной формы (rab), снова обратитесь к таблице 1. Используя SPSS24,
баллов в столбце T1 коррелировали с баллами в столбце B2 (для формы A во время 1 [T1 [и формы B
во время 2 [B2], соответственно), чтобы отразить оценки на двух альтернативные формы теста, проводимого учителем
Калькулятор размера выборки — Демонстрационный тест биномиальной надежности
Калькулятор размера выборки — Демонстрационный тест биномиальной надежности
Метод 1. Этот инструмент вычисляет размер тестовой выборки, необходимый для демонстрации значения надежности на заданном уровне достоверности. Расчет основан на следующем биномиальном уравнении:
Расчет основан на следующем биномиальном уравнении:
где:
C — уровень достоверности теста
R — надежность, которую необходимо продемонстрировать
f — количество допустимых ошибок теста
n — размер тестовой выборки
При заданных входных данных C, R и f, этот инструмент решает указанное выше уравнение для размера выборки n.
Метод 2. Метод 2 использует распределение Вейбулла для определения надежности R для приведенного выше уравнения. Учитывая требования к надежности R rqmt на время миссии T mission
и значение параметра формы Вейбулла β, функция надежности Вейбулла
решается для характерного срока службы (η). Это полностью определяет функцию надежности Вейбулла и
позволяет рассчитать любую другую точку на приведенной ниже кривой. R test , связанный с некоторым доступным временем теста T test , затем вычисляется и используется в приведенном выше
уравнение для расчета количества необходимых тестовых образцов. Демонстрация теста R во время T теста эквивалентна демонстрации R rqmt при условии, что
Демонстрация теста R во время T теста эквивалентна демонстрации R rqmt при условии, что
оценка β точна. Метод 2A подходит для требуемого размера выборки. И наоборот, учитывая фиксированное количество образцов, метод 2B рассчитывает необходимое время испытания.
.
Расчетные данные:
Toolkit Home
Комментарии / Вопросы / Консультации:
Надежностьаналитика.com
Артикул:
- http://www.itl.nist.gov/div898/handbook/prc/section2/prc241.htm.
- MIL-HDBK-338, Руководство по проектированию надежности электронных устройств.
- http://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval
- http://en.wikipedia.org/wiki/Binomial_distribution
- http://reliabilityanalyticstoolkit.appspot.com/binomial_confidence
- Мэтьюз, Пол Расчеты размера выборки: практические методы для инженеров и ученых.
- Райан, Томас П. Определение размера выборки и мощность.
- Collani, E. von; Драгер, Клаус Справочник по биномиальному распределению для ученых и инженеров.
- Расчет размеров тестовых образцов с помощью Microsoft Excel.xlsx
Авторские права © 2010 — 2020 Reliability Analytics Corporation
Все содержимое и материалы на этом сайте предоставляются «как есть» Reliability Analytics не дает никаких гарантий, явных или подразумеваемых, включая гарантии товарной пригодности и пригодности
конкретное назначение; и не принимает на себя никаких юридических обязательств или ответственности за точность, полноту или полезность любой раскрытой информации, устройств, продуктов или процессов;
и не означает, что его использование не нарушит права частной собственности.
Глава 5 Надежность | Введение в образовательные и психологические измерения с использованием R
С точки зрения творческого мыслителя или новатора последовательность может рассматриваться как проблема. Последовательное мышление ведет к тому же, поскольку ограничивает разнообразие и изменения. С другой стороны, непоследовательное мышление или нестандартное мышление порождают новые методы и идеи, изобретения и прорывы, ведущие к инновациям и росту.
Последовательное мышление ведет к тому же, поскольку ограничивает разнообразие и изменения. С другой стороны, непоследовательное мышление или нестандартное мышление порождают новые методы и идеи, изобретения и прорывы, ведущие к инновациям и росту.
Стандартизованные тесты разработаны так, чтобы быть последовательными, и по самой своей природе они, как правило, плохо отражают творческое мышление.Фактически, конструкт творчества — один из самых труднодостижимых в образовательном и психологическом тестировании. Несмотря на то, что существуют опубликованные тесты творческого мышления и решения проблем, процедуры администрирования сложны, и согласованность итоговых оценок, что неудивительно, может быть очень низкой. Креативность, кажется, предполагает непоследовательность в мышлении и поведении, которую сложно надежно измерить.
С точки зрения тестировщика или тестируемого, а именно такой точки зрения мы придерживаемся в этой книге, согласованность критически важна для достоверных измерений. Непоследовательный или ненадежный тест дает ненадежные результаты, которые лишь противоречиво подтверждают предполагаемые выводы теста. Почти столетие исследований дает нам основу для изучения и понимания надежности результатов тестов и, что наиболее важно, того, как можно оценить и улучшить надежность.
Непоследовательный или ненадежный тест дает ненадежные результаты, которые лишь противоречиво подтверждают предполагаемые выводы теста. Почти столетие исследований дает нам основу для изучения и понимания надежности результатов тестов и, что наиболее важно, того, как можно оценить и улучшить надежность.
Эта глава знакомит с надежностью в рамках модели классической теории тестов (CTT), которая затем распространяется на теорию обобщаемости (G). В главе 7 мы узнаем о надежности в рамках модели теории реакции элемента.Все эти теории включают модели измерения, иногда называемые моделями скрытых переменных, которые используются для описания конструкции или конструкций, которые, как предполагается, лежат в основе ответов на тестовые задания.
Эта глава начинается с общего определения надежности с точки зрения согласованности измерений. Затем модель и допущения CTT представлены в связи с моделями статистических выводов и измерений, которые были представлены в главе 1. Надежность и ненадежность, то есть стандартная ошибка измерения, обсуждаются как продукты CTT, а также четыре основных дизайна исследования. рассмотрены соответствующие методы оценки надежности.Наконец, надежность обсуждается в ситуациях, когда оценки поступают от рейтеров. Это называется межэкспертной надежностью, и ее лучше всего концептуализировать с помощью теории G.
рассмотрены соответствующие методы оценки надежности.Наконец, надежность обсуждается в ситуациях, когда оценки поступают от рейтеров. Это называется межэкспертной надежностью, и ее лучше всего концептуализировать с помощью теории G.
В этой главе мы проведем анализ надежности данных PISA09 с помощью epmr и построим график результатов с помощью ggplot2. Мы также смоделируем некоторые данные и проверим межэкспертную надежность с помощью epmr.
Стабильность измерения
В образовательном и психологическом тестировании надежность относится к точности процесса измерения или стабильности результатов теста.Надежность — необходимое условие действительности. То есть, чтобы оценки были достоверными индикаторами предполагаемых выводов или использования теста, они сначала должны быть надежными или точно измеренными. Однако точность или последовательность результатов тестов не обязательно указывает на их валидность.
Простая аналогия может помочь прояснить различие между надежностью и действительностью. Если процесс тестирования представлен соревнованием по стрельбе из лука, в котором испытуемый, лучник, получает несколько попыток поразить центр цели, каждую стрелу можно рассматривать как повторное измерение конструкции способности стрельбы из лука.Представьте себе человека, чьи стрелы попадают в несколько миллиметров друг от друга, плотно сгруппированные вместе, но все они застревают в стволе дерева, стоящего за самой целью. Это представляет собой последовательные, но неточные измерения. С другой стороны, представьте себе другого лучника, стрелы которого разбросаны по цели, причем один попадает близко к цели, а остальные широко распространяются вокруг него. Это измерение является непоследовательным и неточным, хотя, возможно, более точным, чем у первого лучника.И надежность, и достоверность присутствуют только тогда, когда все стрелки находятся близко к центру цели. В этом случае мы постоянно измеряем то, что намереваемся измерить.
Если процесс тестирования представлен соревнованием по стрельбе из лука, в котором испытуемый, лучник, получает несколько попыток поразить центр цели, каждую стрелу можно рассматривать как повторное измерение конструкции способности стрельбы из лука.Представьте себе человека, чьи стрелы попадают в несколько миллиметров друг от друга, плотно сгруппированные вместе, но все они застревают в стволе дерева, стоящего за самой целью. Это представляет собой последовательные, но неточные измерения. С другой стороны, представьте себе другого лучника, стрелы которого разбросаны по цели, причем один попадает близко к цели, а остальные широко распространяются вокруг него. Это измерение является непоследовательным и неточным, хотя, возможно, более точным, чем у первого лучника.И надежность, и достоверность присутствуют только тогда, когда все стрелки находятся близко к центру цели. В этом случае мы постоянно измеряем то, что намереваемся измерить.
Ключевым предположением в этой аналогии является то, что наши лучники действительно опытные, и любые ошибки в их выстрелах связаны с самим процессом измерения. Напротив, постоянные удары по ближайшему дереву могут быть доказательством надежного теста для человека, который просто не попадает в цель, потому что не знает, как целиться.В действительности, если кто-то систематически набирает баллы не по плану или выше или ниже его истинных базовых способностей, нам трудно приписать это предвзятости в процессе тестирования по сравнению с истинной разницей в способностях.
Напротив, постоянные удары по ближайшему дереву могут быть доказательством надежного теста для человека, который просто не попадает в цель, потому что не знает, как целиться.В действительности, если кто-то систематически набирает баллы не по плану или выше или ниже его истинных базовых способностей, нам трудно приписать это предвзятости в процессе тестирования по сравнению с истинной разницей в способностях.
Ключевым моментом здесь является то, что доказательства, подтверждающие надежность теста, могут быть основаны на результатах самого теста. Однако доказательства, подтверждающие достоверность теста, должны частично поступать из внешних источников. Единственные способы определить, что постоянное попадание в дерево представляет собой низкую способность, — это а) подтвердить, что наш тест беспристрастен, и б) провести отдельный тест.Это вопросы действительности, которые будут рассмотрены в Главе 9.
Учитывайте надежность других известных физических измерений. Один из распространенных примеров — измерение веса. Как измерения базовой напольной шкалы могут быть недостоверными и недостоверными? Подумайте о потенциальных источниках ненадежности и недействительности. Например, подумайте об измерении веса маленького ребенка каждый день перед школой. Какую переменную мы на самом деле измеряем? Как эта переменная может меняться день ото дня? И как эти изменения могут быть отражены в наших ежедневных измерениях? Если наши измерения меняются день ото дня, насколько это изменение можно отнести к фактическим изменениям веса по сравнению с посторонними факторами, такими как погода или сбои в самих весах?
Как измерения базовой напольной шкалы могут быть недостоверными и недостоверными? Подумайте о потенциальных источниках ненадежности и недействительности. Например, подумайте об измерении веса маленького ребенка каждый день перед школой. Какую переменную мы на самом деле измеряем? Как эта переменная может меняться день ото дня? И как эти изменения могут быть отражены в наших ежедневных измерениях? Если наши измерения меняются день ото дня, насколько это изменение можно отнести к фактическим изменениям веса по сравнению с посторонними факторами, такими как погода или сбои в самих весах?
В обоих этих примерах есть несколько взаимосвязанных источников потенциальной несогласованности в процессе измерения.Эти источники изменения оценок можно разделить на три категории. Во-первых, сама конструкция может фактически меняться от одного измерения к другому. Например, это происходит, когда практические эффекты или рост со временем приводят к повышению производительности. Лучники могут стрелять более точно по мере калибровки лука или корректировки скорости ветра с каждой стрелой. При тестировании достижений учащиеся могут изучать или, по крайней мере, получать новые знания о содержании теста по мере его прохождения.
При тестировании достижений учащиеся могут изучать или, по крайней мере, получать новые знания о содержании теста по мере его прохождения.
Во-вторых, сам процесс тестирования может отличаться в зависимости от случая измерения.Возможно, сегодня будет сильный ветер, но не завтра. Или, может быть, судьи соревнований выделяют разное количество времени на разминку. Или, может быть, публика шумная или неприятная в одних моментах и благосклонная в других. Эти факторы связаны с самим процессом тестирования, и все они могут привести к изменению оценок.
Наконец, наш тест может быть просто ограничен по объему. Несмотря на все наши усилия, может случиться так, что стрелки в какой-то степени отличаются друг от друга по балансу или конструкции.Или может случиться так, что пальцы лучников иногда соскальзывают не по своей вине. При использовании ограниченного количества снимков оценки могут меняться или отличаться друг от друга просто из-за ограниченного характера теста. Если распространить аналогию на другие виды спорта, футбол и баскетбол, каждый из которых предполагает множество возможностей для набора очков, которые можно использовать для представления способностей игрока или команды. С другой стороны, из-за нехватки голов в футболе один матч может неточно отражать способности, особенно когда судьи были подкуплены!
С другой стороны, из-за нехватки голов в футболе один матч может неточно отражать способности, особенно когда судьи были подкуплены!
Классическая теория испытаний
Модель
Теперь, когда у нас есть определение надежности с примерами несоответствий, которые могут повлиять на результаты тестов, мы можем создать основу для оценки надежности на основе изменений или вариативности, которые происходят в наборе оценок тестов.Вспомните из главы 1, что статистика позволяет нам сделать вывод от а) изменений, которые мы наблюдаем в наших оценках за тесты, до б) того, что, как мы предполагаем, является основной причиной этих изменений, конструктом. Надежность основывается и оценивается в рамках простой модели измерения, которая разлагает наблюдаемый результат теста \ (X \) на две части: истина \ (T \) и ошибка \ (E \):
\ [\ begin {уравнение}
Х = Т + Е.
\ tag {5.1}
\ end {Equation} \]
Обратите внимание, что \ (X \) в уравнении (5.1) является составной частью, состоящей из двух компонентных оценок. Истинная оценка \ (T \) — это конструкция, которую мы собираемся измерить. Мы предполагаем, что \ (T \) влияет на наше наблюдение в \ (X \). Оценка ошибки \ (E \) — это все, что случайно не связано с конструкцией, которую мы собираемся измерить. Ошибка также напрямую влияет на наши наблюдения.
Истинная оценка \ (T \) — это конструкция, которую мы собираемся измерить. Мы предполагаем, что \ (T \) влияет на наше наблюдение в \ (X \). Оценка ошибки \ (E \) — это все, что случайно не связано с конструкцией, которую мы собираемся измерить. Ошибка также напрямую влияет на наши наблюдения.
Чтобы понять модель CTT в уравнении (5.1), мы должны понять следующий вопрос: как наблюдаемый балл человека \ (X \) будет меняться при многократном повторении теста? Если вы проходите тест каждый день в течение следующих 365 дней и каким-то образом забыли обо всех предыдущих процедурах тестирования, изменится ли ваш наблюдаемый результат от одного тестирования к другому? И если да, то почему это должно измениться?
CTT отвечает на этот вопрос, делая два ключевых предположения об изменчивости и ковариабельности \ (T \) и \ (E \).Во-первых, ваша истинная основная способность \ (T \) считается постоянной для человека. Если ваши истинные способности могут быть выражены как 20 из 25 возможных баллов, каждый раз, когда вы будете проходить тест, ваша истинная оценка будет постоянно равняться 20. Согласно CTT, она не изменится. Во-вторых, предполагается, что ошибка, которая влияет на наблюдаемую оценку для данной администрации, является полностью случайной и, таким образом, не связана с вашей истинной оценкой и любой другой оценкой ошибки для другой администрации.
Согласно CTT, она не изменится. Во-вторых, предполагается, что ошибка, которая влияет на наблюдаемую оценку для данной администрации, является полностью случайной и, таким образом, не связана с вашей истинной оценкой и любой другой оценкой ошибки для другой администрации.
Итак, при одном проведении теста какая-то ошибка может привести к снижению вашего результата на два балла.Может, в тот день ты плохо себя чувствовал. В этом случае, зная, что \ (T = 20 \), что такое \ (E \) в уравнении (5.1) и что такое \ (X \)? В другой администрации вы можете правильно угадать несколько вопросов теста, что приведет к увеличению числа на 3 исключительно из-за ошибки. Что сейчас есть \ (E \)? А что такое \ (X \)?
Решение для \ (E \) в уравнении (5.1) поясняет, что случайная ошибка — это просто разница между истинной оценкой и наблюдением, где отрицательная ошибка всегда указывает, что \ (X \) слишком низка, а положительная ошибка всегда указывает на то, что что \ (X \) слишком велико:
\ [\ begin {уравнение}
E = X — T. \ tag {5.2}
\ tag {5.2}
\ end {Equation} \]
Итак, простуда дает \ (E = -2 \) и \ (X = 18 \), по сравнению с вашим истинным баллом 20. А правильное угадывание дает \ (E = 3 \) и \ (X = 23 \ ).
Согласно CTT, за бесконечное количество запусков теста без практических эффектов ваша истинная оценка всегда будет одинаковой, а оценки ошибок будут варьироваться совершенно случайным образом, некоторые из них будут положительными, другие отрицательными, но в среднем равны нулю. С учетом этих предположений, какой должна быть ваша средняя наблюдаемая оценка за бесконечное количество раз в тесте? И каким должно быть стандартное отклонение вашей наблюдаемой оценки от этих бесконечных наблюдаемых оценок? Отвечая на эти вопросы, вам не нужно указывать конкретные значения, вместо этого вы должны ссылаться на средние значения и стандартные отклонения, которые, по вашему мнению, будут иметь \ (T \) и \ (E \).Помните, что \ (X \) полностью выражается как функция от \ (T \) и \ (E \), поэтому мы можем вывести свойства композита из его компонентов.
# Имитация постоянного истинного значения и случайного изменения
# оценка ошибки из
# нормальная популяция со средним 0 и SD 1
# set.seed () дает R отправную точку для создания
# случайные числа
# чтобы мы могли получить одинаковые результаты на разных компьютерах
# Вы должны проверить среднее и стандартное отклонение E и X
# Создание гистограммы X тоже может быть интересно
установленный.семя (160416)
myt <- 20
mye <- rnorm (1000, среднее = 0, sd = 1)
myx <- myt + mye Вот объяснение вышеперечисленных вопросов. Мы знаем, что ваш средний наблюдаемый балл будет вашим истинным баллом. Ошибка, поскольку она изменяется случайным образом, в конечном итоге компенсируется сама собой, и ваш средний наблюдаемый результат \ (X \) будет просто \ (T \). Стандартное отклонение этих бесконечных наблюдаемых оценок \ (X \) было бы тогда полностью вызвано ошибкой. Поскольку истина не меняется, любое изменение наблюдаемых оценок должно быть изменчивостью ошибок.Это стандартное отклонение называется стандартной ошибкой измерения (SEM) (SEM), более подробно описанной ниже. Хотя теоретически невозможно получить фактический SEM, поскольку вы никогда не можете проходить тест бесконечное количество раз, мы можем оценить SEM, используя данные из выборки тестируемых. И, как мы увидим ниже, надежность будет оцениваться как противоположность погрешности измерения.
Хотя теоретически невозможно получить фактический SEM, поскольку вы никогда не можете проходить тест бесконечное количество раз, мы можем оценить SEM, используя данные из выборки тестируемых. И, как мы увидим ниже, надежность будет оцениваться как противоположность погрешности измерения.
На рис. 5.1 представлены три части модели CTT с использованием PISA09 общих баллов по чтению для студентов из Бельгии.Здесь мы переходим от множества оценок \ (X \) и \ (E \) для человека с константой \ (T \) к \ (X \), \ (T \) и \ (E \) балл для каждого человека в выборке. Общие оценки чтения на оси абсцисс представляют \ (X \), а имитированные оценки \ (T \) - на оси ординат. Эти общие баллы рассчитываются как \ (T = X - E \). Сплошная линия представляет то, что мы ожидали бы, если бы не было ошибки, и в этом случае \ (X \) = \ (T \). В результате горизонтальный разброс на графике представляет \ (E \). Обратите внимание, что \ (T \) моделируются как непрерывные и могут находиться в диапазоне от 0 до 11. Показатели \ (X \) дискретны, но они слегка «дрожат» слева направо, чтобы показать плотность точек на графике.
Показатели \ (X \) дискретны, но они слегка «дрожат» слева направо, чтобы показать плотность точек на графике.
# Подсчитайте общий балл по чтению, как в главе 2
ritems <- c ("r414q02", "r414q11", "r414q06", "r414q09",
«r452q03», «r452q04», «r452q06», «r452q07», «r458q01»,
«r458q07», «r458q04»)
rsitems <- paste0 (ritems, "s")
xscores <- rowSums (PISA09 [PISA09 $ cnt == "BEL", rsitems],
na.rm = ИСТИНА)
# Смоделировать оценки ошибок на основе известного SEM 1,4, который
# мы посчитаем позже, а затем создадим истинные оценки
# Истинные оценки усекаются до 0 и 11 с использованием
# setrange ()
escores <- rnorm (длина (xscores), 0, 1.4)
tscores <- setrange (xscores - escores, y = xscores)
# Объедините во фрейме данных и создайте диаграмму рассеяния
оценки <- data.frame (x1 = xscores, t = tscores,
e = escores)
ggplot (scores, aes (x1, t)) +
geom_point (позиция = position_jitter (w = .3)) +
geom_abline (col = "blue") Рисунок 5.1: Общий балл по чтению PISA с смоделированной ошибкой и истинный балл на основе CTT.
Рассмотрим людей с истинной оценкой \ (T = 6 \). Идеальный тест мог бы идеально измерить истинные баллы и выдать наблюдаемые баллы \ (X = T = 6 \) на сплошной линии.На самом деле, многие люди набрали \ (T = 6 \) или около того, но их фактические оценки по \ (X \) варьировались от примерно \ (X = 3 \) до \ (X = 9 \). Опять же, любое горизонтальное расстояние от синей линии для данной истинной оценки представляет \ (E \).
Приложения модели
Давайте теперь подумаем о некоторых конкретных примерах классической модели теории тестирования. Подумайте о конструкции, которая вас интересует, о том, как эта конструкция реализуется, и о том, какую шкалу измерения она создает. Рассмотрите возможный диапазон оценок и попробуйте сформулировать \ (X \) и \ (T \) в вашем собственном примере.
Теперь давайте подумаем о \ (E \). Что может привести к тому, что наблюдаемая оценка человека \ (X \) будет отличаться от ее истинной оценки \ (T \) в этой ситуации? Подумайте об условиях, в которых будет проводиться тест. Подумайте о группе студентов, пациентов, людей, с которыми вы работаете. Будут ли они иметь тенденцию вносить некоторую форму ошибки или ненадежности в процесс измерения?
Подумайте о группе студентов, пациентов, людей, с которыми вы работаете. Будут ли они иметь тенденцию вносить некоторую форму ошибки или ненадежности в процесс измерения?
Вот простой пример с дошкольниками. Как я упоминал в предыдущих главах, некоторые из моих исследований связаны с оценкой ранней грамотности.В этом исследовании мы проверяем фонологическую осведомленность детей, предлагая им целевое изображение, например изображение звезды, и прося их идентифицировать изображение среди трех вариантов ответа, которое рифмуется с целевым изображением. Итак, мы представляем изображения и спрашиваем: «Какое из них рифмуется со звездой?» Затем, например, дети могут указать на изображение автомобиля.
Ошибка измерения в таком тесте проблематична по ряду причин. Во-первых, дошкольники легко отвлекаются.Даже при проведении стандартизированного индивидуального тестирования отдельно от остального класса дети могут быть отвлечены множеством, казалось бы, безобидных особенностей администрации или окружающей среды, от стула, на котором они сидят, до молнии на куртке. . В отсутствие каких-либо вещей в их окружении они будут рассказывать вам о вещах из дома, о том, что они ели на завтрак, что они делали на выходных, или, в крайнем случае, о вещах, выдвинутых их воображением. Во-вторых, из-за их непродолжительного внимания сам тест должен быть кратким и простым в проведении.Более короткие тесты, как упоминалось выше в отношении стрельбы из лука и других видов спорта, являются менее надежными тестами; меньшее количество элементов затрудняет определение надежной части процесса измерения. В более коротких тестах проблемы с отдельными элементами имеют большее влияние на тест в целом.
. В отсутствие каких-либо вещей в их окружении они будут рассказывать вам о вещах из дома, о том, что они ели на завтрак, что они делали на выходных, или, в крайнем случае, о вещах, выдвинутых их воображением. Во-вторых, из-за их непродолжительного внимания сам тест должен быть кратким и простым в проведении.Более короткие тесты, как упоминалось выше в отношении стрельбы из лука и других видов спорта, являются менее надежными тестами; меньшее количество элементов затрудняет определение надежной части процесса измерения. В более коротких тестах проблемы с отдельными элементами имеют большее влияние на тест в целом.
Подумайте, что случилось бы с \ (E \) и стандартным отклонением \ (E \), если бы тест был очень коротким, возможно, включающим только пять тестовых вопросов. Что произойдет с \ (E \) и его стандартным отклонением, если мы увеличим количество вопросов до 200? Что может случиться с \ (E \) и его стандартным отклонением, если мы проведем тест снаружи? На эти типы вопросов мы ответим, рассмотрев конкретные источники ошибок измерения и ожидаемое от них влияние, будь то систематическое или случайное, на нашу наблюдаемую оценку.
Систематическая и случайная ошибка
Систематическая ошибка - это ошибка, которая одинаково влияет на оценку человека при каждом повторном введении. Случайная ошибка - это ошибка, которая может быть положительной или отрицательной для человека или случайно изменяемая администрацией. В примере с грамотностью дошкольников, поскольку учащиеся меньше сосредотачиваются на самом тесте и больше на своем окружении, их оценки могут включать больше предположений, что приводит к случайной ошибке, если предположить, что это действительно случайное предположение.Интересно, что в пилотных исследованиях оценки ранней грамотности мы заметили, что некоторые учащиеся, как правило, выбирали первый вариант, когда не знали правильного ответа. Это привело к систематическому изменению их оценок в зависимости от того, как часто правильный ответ оказывался первым.
Отличить систематическую ошибку от случайной может быть сложно. Некоторые особенности теста или его администрирования могут приводить к ошибкам обоих типов. Популярный пример систематической ошибки в сравнении со случайной ошибкой демонстрирует неправильная шкала пола.Возвращаясь к приведенному выше примеру, предположим, что я измеряю вес своего старшего сына каждый день в течение двух недель, как только он возвращается из школы. Для контекста, моему самому старшему на момент написания этой статьи было одиннадцать лет. Предположим также, что его средний вес за две недели составлял 60 фунтов, но это варьировалось со стандартным отклонением в 5 фунтов. Подумайте о некоторых причинах такого большого стандартного отклонения. Что могло привести к тому, что вес моего сына по половым весам может отличаться от его истинного веса при заданном измерении? А как насчет его одежды? Или сколько игрушек у него в карманах? Или сколько еды он съел на обед?
Популярный пример систематической ошибки в сравнении со случайной ошибкой демонстрирует неправильная шкала пола.Возвращаясь к приведенному выше примеру, предположим, что я измеряю вес своего старшего сына каждый день в течение двух недель, как только он возвращается из школы. Для контекста, моему самому старшему на момент написания этой статьи было одиннадцать лет. Предположим также, что его средний вес за две недели составлял 60 фунтов, но это варьировалось со стандартным отклонением в 5 фунтов. Подумайте о некоторых причинах такого большого стандартного отклонения. Что могло привести к тому, что вес моего сына по половым весам может отличаться от его истинного веса при заданном измерении? А как насчет его одежды? Или сколько игрушек у него в карманах? Или сколько еды он съел на обед?
Какой тип ошибки фиксирует стандартное отклонение , а не ? Систематическая ошибка не меняется от одного измерения к другому.Например, если весы не откалиброваны правильно, они могут постоянно завышать или занижать вес от одного измерения к другому. Здесь важно помнить, что только один тип ошибок фиксируется \ (E \) в CTT: случайная ошибка. Любая систематическая ошибка, которая постоянно возникает между администрациями, станет частью \ (T \) и не снизит нашу оценку надежности.
Здесь важно помнить, что только один тип ошибок фиксируется \ (E \) в CTT: случайная ошибка. Любая систематическая ошибка, которая постоянно возникает между администрациями, станет частью \ (T \) и не снизит нашу оценку надежности.
Надежность и ненадежность
Надежность
Рисунок 5.2 содержит график, аналогичный изображенному на рис. 5.1, где мы определили \ (X \), \ (T \) и \ (E \). На этот раз у нас есть оценки по двум формам теста чтения, первая форма теперь называется \ (X_1 \), а вторая форма - \ (X_2 \), и мы собираемся сосредоточиться на общих расстояниях между точками и точкой. линия, идущая по диагонали сюжета. Еще раз, эта линия олицетворяет истину. Человек с истинным баллом 11 по шкале \ (X_1 \) получит 11 баллов по шкале \ (X_2 \), исходя из предположений модели CTT.
Хотя сплошная линия представляет то, что мы ожидаем увидеть в отношении истинных результатов, мы на самом деле не знаем чьи-либо истинные оценки, даже для тех учащихся, которые получили одинаковые оценки по обеим формам теста. Все точки на Рисунке 5.2 являются наблюдаемыми. Учащиеся, набравшие одинаковые баллы по обеим формам, показывают более последовательные измерения. Однако может оказаться, что их истинная оценка все еще отличается от наблюдаемой. Нет возможности узнать. Чтобы вычислить истину, нам придется проводить тест бесконечное количество раз, а затем вычислять среднее значение или просто моделировать его, как показано на рис. 5.1.
Все точки на Рисунке 5.2 являются наблюдаемыми. Учащиеся, набравшие одинаковые баллы по обеим формам, показывают более последовательные измерения. Однако может оказаться, что их истинная оценка все еще отличается от наблюдаемой. Нет возможности узнать. Чтобы вычислить истину, нам придется проводить тест бесконечное количество раз, а затем вычислять среднее значение или просто моделировать его, как показано на рис. 5.1.
# Имитация оценок для новой формы теста чтения
# называется y
# rho - это надёжность, установленная на 0.80
# x - исходный общий балл за чтение
# Форма y немного проще, чем x со средним значением 6 и SD 3
xysim <- rsim (rho = 0,8, x = оценка $ x1, meany = 6, sdy = 3)
scores $ x2 <- round (setrange (xysim $ y, scores $ x1))
ggplot (scores, aes (x1, x2)) +
geom_point (position = position_jitter (w = .3, h = .3)) +
geom_abline (col = "blue") Рисунок 5.2: Общий балл по чтению PISA и баллы по моделированному второму виду теста по чтению.
Допущения CTT позволяют нам оценить надежность оценок с использованием выборки людей.На рис. 5.2 показаны оценки по двум формам теста, а общий разброс оценок по сплошной линии дает нам представление о линейной зависимости между ними. Кажется, существует сильная, позитивная, линейная связь. Таким образом, люди склонны набирать одинаковые баллы от одной формы к другой, причем более высокие баллы в одной форме соответствуют более высоким баллам в другой. Коэффициент корреляции для этого набора данных, cor (оценка $ x, оценка $ y) = 0,802, дает нам оценку того, насколько похожи оценки в среднем от \ (X_1 \) до \ (X_2 \).Поскольку корреляция для этого графика положительная и сильная, мы ожидаем, что оценка человека будет примерно одинакова от одного тестирования к другому.
Представьте себе, если бы диаграмма рассеяния была почти круглой, без четкого линейного тренда от одной формы теста к другой. Корреляция в этом случае будет близка к нулю. Ожидаем ли мы, что кто-то будет набирать одинаковые баллы от одного теста к другому? С другой стороны, представьте себе диаграмму рассеяния, которая идеально вписывается в линию. Если вы наберете 10 баллов в одной форме, вы также получите 10 баллов в другой.2_X}.
Если вы наберете 10 баллов в одной форме, вы также получите 10 баллов в другой.2_X}.
\ tag {5.3}
\ end {Equation} \]
Обратите внимание, что истинные баллы предполагаются постоянными в CTT для данного человека , но не для разных людей. Таким образом, надежность определяется с точки зрения вариабельности оценок для популяции тестируемых. Почему одни люди получают более высокие баллы, чем другие? Отчасти потому, что у них на самом деле более высокие способности или истинные оценки, чем у других, но также отчасти из-за ошибки измерения. Коэффициент надежности в уравнении (5.3) сообщает нам , насколько наблюдаемой нами изменчивости в \ (X \) обусловлены истинными различиями в оценках.
Оценка надежности
К сожалению, мы никогда не можем узнать истинные результаты CTT для тестируемых. Таким образом, мы должны оценивать надежность косвенно. Одной из косвенных оценок, сделанных CTT, является корреляция между оценками по двум формам одного и того же теста, как показано на Рисунке 5. 2:
2:
\ [\ begin {уравнение}
r = \ rho_ {X_1 X_2} = \ frac {\ sigma_ {X_1 X_2}} {\ sigma_ {X_1} \ sigma_ {X_2}}.
\ tag {5.4}
\ end {Equation} \]
Эта корреляция оценивается как ковариация или общая дисперсия между распределениями в двух формах, деленная на произведение стандартных отклонений или общую доступную дисперсию в каждом распределении.
Существуют и другие методы оценки надежности с помощью одной формы теста. Здесь представлены только надежность с разделением половин и коэффициент альфа. Разделенная половина представлена только потому, что она связана с так называемой формулой надежности Спирмена-Брауна. Метод разделения половин предшествует коэффициенту альфа и является более простым в вычислительном отношении. Он берет баллы по одной форме теста и разделяет их на баллы по двум половинам теста, которые рассматриваются как отдельные тестовые формы.Тогда корреляция между этими двумя половинами представляет собой косвенную оценку надежности, основанную на уравнении (5. 3).
3).
# Разделить половинную корреляцию, предполагая, что у нас есть только оценки
# одна тестовая форма
# При нечетном количестве элементов чтения половина имеет 5
# элемента, а в другом 6
xsplit1 <- rowSums (PISA09 [PISA09 $ cnt == "BEL",
rsitems [1: 5]])
xsplit2 <- rowSums (PISA09 [PISA09 $ cnt == "BEL",
rsitems [6:11]])
cor (xsplit1, xsplit2, use = "complete")
## [1] 0,624843 Формула Спирмена-Брауна первоначально использовалась для корректировки снижения надежности, которое произошло при корреляции двух тестовых форм, длина которых составляла только половину длины исходного теста.Теоретически надежность будет повышаться по мере добавления элементов в тест. Таким образом, метод Спирмена-Брауна используется для оценки или предсказания надежности, если бы тесты половинной длины были преобразованы в тесты полной длины.
# sb_r () в пакете epmr использует метод Spearman-Brown
# формула для оценки того, как изменится надежность, когда
# длина теста изменяется в k раз
# Если бы длина теста была удвоена, k было бы 2
sb_r (r = cor (xsplit1, xsplit2, use = "complete"), k = 2)
## [1] 0,76 Формула Спирмена-Брауна имеет и другие практические применения. Сегодня его чаще всего используют в процессе разработки тестов, чтобы предсказать, как изменится надежность, если форма теста будет уменьшена или увеличена в длину. Например, если вы разрабатываете тест и собираете пилотные данные по 20 тестовым элементам с оценкой надежности 0,60, можно использовать метод Спирмена-Брауна для прогнозирования увеличения этой надежности, если вы увеличите длину теста до 30 или 40 элементов. . Вы также можете пилотно протестировать большое количество элементов, скажем 100, и предсказать, насколько снизится надежность, если вы захотите использовать более короткий тест.
Сегодня его чаще всего используют в процессе разработки тестов, чтобы предсказать, как изменится надежность, если форма теста будет уменьшена или увеличена в длину. Например, если вы разрабатываете тест и собираете пилотные данные по 20 тестовым элементам с оценкой надежности 0,60, можно использовать метод Спирмена-Брауна для прогнозирования увеличения этой надежности, если вы увеличите длину теста до 30 или 40 элементов. . Вы также можете пилотно протестировать большое количество элементов, скажем 100, и предсказать, насколько снизится надежность, если вы захотите использовать более короткий тест.
Надежность Спирмена-Брауна, \ (r_ {new} \), оценивается как функция того, что обозначено здесь как старая надежность, \ (r_ {old} \), и коэффициента, на который длина \ (X \), согласно прогнозам, изменится, \ (k \):
\ [\ begin {уравнение}
r_ {new} = \ frac {kr_ {old}} {(k - 1) r_ {old} + 1}.
\ tag {5.5}
\ end {Equation} \]
Опять же, \ (k \) - коэффициент увеличения или уменьшения длины теста. Он равен количеству элементов в новом тесте, деленному на количество элементов в исходном тесте.Умножьте \ (k \) на старую надежность, а затем разделите результат на \ ((k - 1) \), умноженное на старую надежность, плюс 1. В примере, упомянутом выше, переходя от 20 до 30 элементов, мы имеем \ ((30/20 \ умножить на 0,60) \) разделить на \ ((30/20 - 1) \ умножить на 0,60 + 1 = 0,69 \). Переходя к 40 позициям, мы получаем новую надежность 0,75. Пакет epmr содержит
Он равен количеству элементов в новом тесте, деленному на количество элементов в исходном тесте.Умножьте \ (k \) на старую надежность, а затем разделите результат на \ ((k - 1) \), умноженное на старую надежность, плюс 1. В примере, упомянутом выше, переходя от 20 до 30 элементов, мы имеем \ ((30/20 \ умножить на 0,60) \) разделить на \ ((30/20 - 1) \ умножить на 0,60 + 1 = 0,69 \). Переходя к 40 позициям, мы получаем новую надежность 0,75. Пакет epmr содержит sb_r () , простую функцию для оценки надежности Спирмена-Брауна.
Alpha, пожалуй, самая популярная форма надежности. Многие называют его «альфой Хронбаха», но сам Хронбах никогда не намеревался претендовать на авторство на него, а в последующие годы он сожалел о том, что он был приписан ему (см. Cronbach and Shavelson 2004).2_X \) отражает всю вариативность, доступную в общих баллах за тест. Мы вычитаем из него отклонения, которые уникальны для самих отдельных элементов. Что осталось? Только общая изменчивость между элементами теста. Затем мы делим эту общую изменчивость на общую доступную изменчивость. В формуле для альфа вы должны увидеть общую формулу надежности, истинную дисперсию над наблюдаемой.
Затем мы делим эту общую изменчивость на общую доступную изменчивость. В формуле для альфа вы должны увидеть общую формулу надежности, истинную дисперсию над наблюдаемой.
# epmr включает rstudy (), который оценивает альфа и
# связанная форма надежности, называемая омега, вместе с
# соответствующий SEM
# Вы также можете использовать coef_alpha () для получения коэффициента
# альфа напрямую
rstudy (PISA09 [, rsitems])
##
## Исследование надежности
##
## Количество элементов: 11
##
## Количество дел: 44878
##
## Оценки:
## coef sem
## альфа 0.760 1,40
## омега 0,763 1,39 Имейте в виду, что альфа - это оценка надежности, как и корреляция. Таким образом, любое уравнение, требующее оценки надежности, например SEM ниже, может быть вычислено с использованием либо коэффициента корреляции, либо альфа-коэффициента. Студенты часто не согласны с этим: корреляция - это одна оценка надежности, альфа - другая. Они оба оценивают одно и то же, но по-разному, основываясь на разных планах исследования надежности.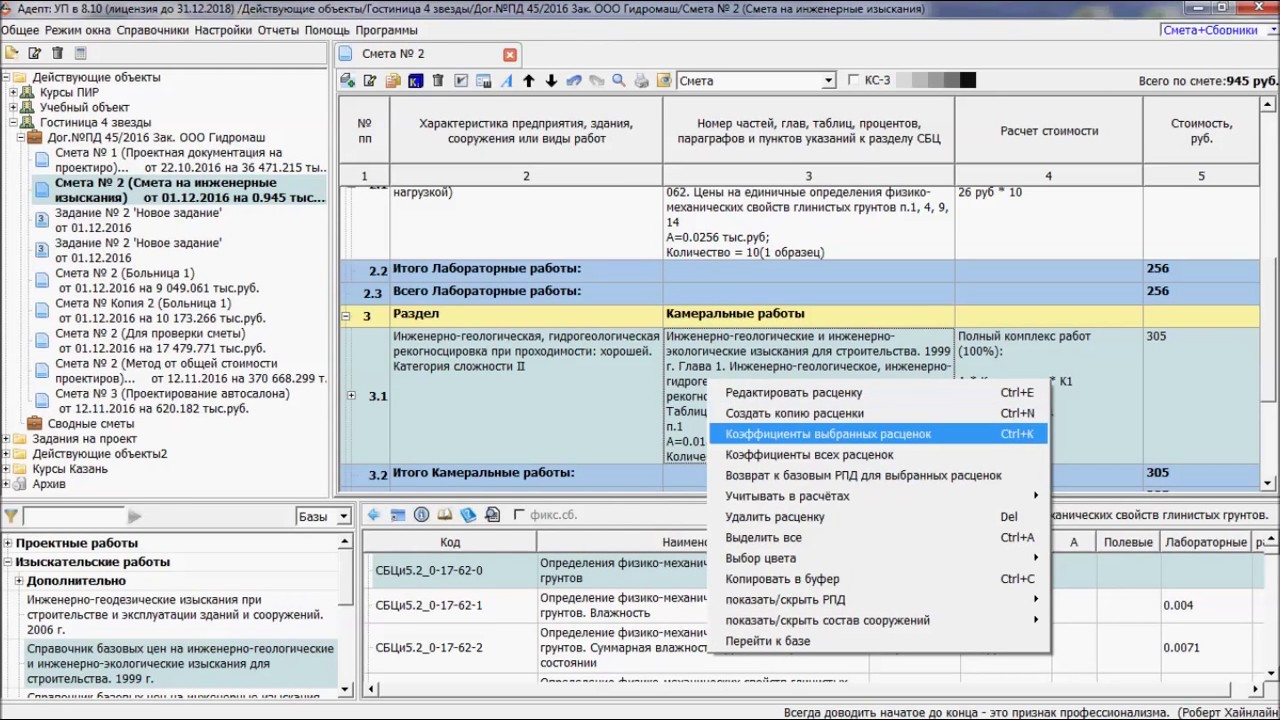
ненадежность
Теперь, когда мы определили надежность с точки зрения доли наблюдаемой дисперсии, которая является истинной, мы можем определить ненадежность как часть наблюдаемой дисперсии, которая является ошибкой.2_X}.
\ tag {5.7}
\ end {Equation} \]
Обычно нас больше интересует, как ненадежность теста может быть выражена в терминах доступной наблюдаемой изменчивости. Таким образом, мы умножаем ненадежную долю дисперсии на стандартное отклонение \ (X \), чтобы получить SEM:
\ [\ begin {уравнение}
SEM = \ sigma_X \ sqrt {1 - r}.
\ tag {5.8}
\ end {Equation} \]
SEM - это средняя изменчивость наблюдаемых оценок, связанная с ошибкой. Как и любую стандартную статистическую ошибку, его можно использовать для создания доверительного интервала (ДИ) вокруг статистики, которую он оценивает, то есть \ (T \).Поскольку у нас нет \ (T \), мы вместо этого создаем доверительный интервал вокруг \ (X \), чтобы показать, насколько мы уверены, что \ (T \) подпадает под него для данного человека. Например, сообщается, что подтест вербального мышления GRE имеет надежность 0,93 и SEM 2,2 по шкале от 130 до 170. Таким образом, наблюдаемая оценка вербального мышления, равная 155, имеет 95% доверительный интервал около \ (\ pm 4.4 \) баллов. При \ (X = 155 \) мы на 95% уверены, что истинный результат находится где-то между 150.8 и 159.2. (Обратите внимание, что баллы по GRE фактически оцениваются с использованием IRT.)
Например, сообщается, что подтест вербального мышления GRE имеет надежность 0,93 и SEM 2,2 по шкале от 130 до 170. Таким образом, наблюдаемая оценка вербального мышления, равная 155, имеет 95% доверительный интервал около \ (\ pm 4.4 \) баллов. При \ (X = 155 \) мы на 95% уверены, что истинный результат находится где-то между 150.8 и 159.2. (Обратите внимание, что баллы по GRE фактически оцениваются с использованием IRT.)
Доверительные интервалы для PISA09 можно оценить таким же образом. Сначала мы выбираем меру надежности, находим SD наблюдаемых оценок и получаем соответствующий SEM. Затем мы можем найти CI, который дает нам ожидаемую степень неопределенности в наших наблюдаемых оценках из-за случайной ошибки измерения. Здесь мы вычисляем SEM и CI с использованием альфы, но подойдут и другие оценки надежности.На рис. 5.3 показаны 11 возможных баллов по чтению ( PISA09 ) по порядку с планками ошибок, основанными на SEM, для студентов из Бельгии.
# Получить альфа-версию и SEM для студентов в Бельгии
bela <- coef_alpha (PISA09 [PISA09 $ cnt == "BEL", rsitems]) $ alpha
# Функция sem из epmr иногда перекрывается с функцией sem из
# еще один пакет R, так что мы подробно рассмотрим его здесь
# форма
belsem <- epmr :: sem (r = bela, sd = sd (получает $ x1,
na. rm = T))
# Постройте 11 возможных общих оценок против самих себя
# Индикаторы ошибок показаны для 1 SEM, что дает 68% достоверности
# интервал и 2 SEM, что дает 95% доверительный интервал
# x преобразуется в коэффициент, чтобы отображать дискретные значения на
# ось x
beldat <- данные.рамка (x = 1:11, sem = belsem)
ggplot (beldat, aes (factor (x), x)) +
geom_errorbar (aes (ymin = x - sem * 2,
ymax = x + sem * 2), col = "фиолетовый") +
geom_errorbar (aes (ymin = x - sem, ymax = x + sem),
col = "желтый") +
geom_point ()  rm = T))
# Постройте 11 возможных общих оценок против самих себя
# Индикаторы ошибок показаны для 1 SEM, что дает 68% достоверности
# интервал и 2 SEM, что дает 95% доверительный интервал
# x преобразуется в коэффициент, чтобы отображать дискретные значения на
# ось x
beldat <- данные.рамка (x = 1:11, sem = belsem)
ggplot (beldat, aes (factor (x), x)) +
geom_errorbar (aes (ymin = x - sem * 2,
ymax = x + sem * 2), col = "фиолетовый") +
geom_errorbar (aes (ymin = x - sem, ymax = x + sem),
col = "желтый") +
geom_point ()
rm = T))
# Постройте 11 возможных общих оценок против самих себя
# Индикаторы ошибок показаны для 1 SEM, что дает 68% достоверности
# интервал и 2 SEM, что дает 95% доверительный интервал
# x преобразуется в коэффициент, чтобы отображать дискретные значения на
# ось x
beldat <- данные.рамка (x = 1:11, sem = belsem)
ggplot (beldat, aes (factor (x), x)) +
geom_errorbar (aes (ymin = x - sem * 2,
ymax = x + sem * 2), col = "фиолетовый") +
geom_errorbar (aes (ymin = x - sem, ymax = x + sem),
col = "желтый") +
geom_point () Рисунок 5.3: Шкала показаний PISA09 с доверительными интервалами 68 и 95 процентов вокруг каждой точки.
Рисунок 5.3 помогает нам визуализировать влияние ненадежных измерений на сравнение оценок. Например, обратите внимание, что верхняя часть 95% доверительного интервала для \ (X \) из 2 простирается почти до 5 баллов и, таким образом, перекрывается с доверительным интервалом для соседних оценок с 3 по 7.Только после \ (X \) из 8 CI больше не перекрываются. С ДИ
С ДИ белсем 1,425, мы на 95% уверены, что ученики с наблюдаемыми баллами, отличающимися по крайней мере на белсем * 4 5,7, имеют разные истинные баллы. Студенты с наблюдаемыми баллами ближе, чем белсэм * 4 , на самом деле могут иметь такие же истинные баллы.
Толкование надежности и ненадежности
Нет никаких согласованных стандартов для интерпретации коэффициентов надежности. Надежность ограничивается 0 на нижнем конце и 1 на верхнем, потому что, по определению, величина истинной изменчивости никогда не может быть меньше или больше, чем общая доступная изменчивость в \ (X \).Чем выше надежность, тем лучше, но пороговые значения приемлемых уровней надежности различаются для разных областей, ситуаций и типов тестов. Ставки теста являются важным фактором при интерпретации коэффициентов надежности. Чем выше ставки, тем выше ожидаемая надежность. В противном случае ограничения зависят от конкретного приложения.
В целом надежность образовательных и психологических тестов можно интерпретировать с помощью шкал, подобных шкалам, представленным в таблице 5. 1. В тестах со средними ставками надежность 0,70 иногда считается минимально приемлемой, 0,80 - приличной, 0,90 - вполне хорошей и все, что выше 0,90 - отлично. Тесты с высокими ставками должны иметь надежность не ниже 0,90. Тесты с низкими ставками, которые часто проще и короче, чем тесты с более высокими ставками, часто имеют надежность всего 0,70. Это общие рекомендации, и их толкование может значительно различаться в зависимости от теста. Помните, что когнитивные показатели в PISA будут считаться низкими на уровне учащихся.
1. В тестах со средними ставками надежность 0,70 иногда считается минимально приемлемой, 0,80 - приличной, 0,90 - вполне хорошей и все, что выше 0,90 - отлично. Тесты с высокими ставками должны иметь надежность не ниже 0,90. Тесты с низкими ставками, которые часто проще и короче, чем тесты с более высокими ставками, часто имеют надежность всего 0,70. Это общие рекомендации, и их толкование может значительно различаться в зависимости от теста. Помните, что когнитивные показатели в PISA будут считаться низкими на уровне учащихся.
При интерпретации коэффициента альфа необходимо учитывать несколько дополнительных факторов. Во-первых, альфа предполагает, что все элементы измеряют одну и ту же единую конструкцию. Предполагается, что элементы в равной степени связаны с этой конструкцией, то есть предполагается, что они являются параллельными измерениями конструкции. Когда элементы не являются параллельными мерами конструкции, альфа считается нижней оценкой надежности, то есть ожидается, что истинная надежность для теста будет выше, чем указанная альфа. Наконец, альфа не является мерой размерности. Часто утверждают, что сильный коэффициент альфа поддерживает одномерность меры. Однако альфа не индексирует размерность. На него влияет степень, в которой все элементы теста измеряют одну конструкцию, но она не обязательно повышается или понижается по мере того, как тест становится более или менее одномерным.
Наконец, альфа не является мерой размерности. Часто утверждают, что сильный коэффициент альфа поддерживает одномерность меры. Однако альфа не индексирует размерность. На него влияет степень, в которой все элементы теста измеряют одну конструкцию, но она не обязательно повышается или понижается по мере того, как тест становится более или менее одномерным.
| \ (\ geq 0.90 \) | Отлично | Отлично |
| \ (0,80 \ leq r <0,90 \) | Хорошо | Отлично |
| \ (0,70 \ leq r <0,80 \) | приемлемо | Хорошо |
| \ (0,60 \ leq r <0,70 \) | Граница | приемлемо |
| \ (0,50 \ leq r <0,60 \) | Низкий | Граница |
| \ (0,20 \ leq r <0,50 \) | неприемлемо | Низкая |
\ (0. 00 \ leq r <0,20 \) 00 \ leq r <0,20 \) | неприемлемо | неприемлемо |
Дизайн исследования надежности
Теперь, когда мы установили наиболее распространенные оценки надежности и ненадежности, мы можем обсудить четыре основных плана исследования, которые позволяют нам собирать данные для наших оценок. Эти конструкции называются планами внутренней согласованности, эквивалентности, стабильности и эквивалентности / стабильности. Каждая конструкция обеспечивает соответствующий тип надежности, на которую, как ожидается, будут влиять различные источники ошибок измерения.
Четыре стандартных дизайна исследования различаются по количеству форм тестирования и количеству случаев тестирования, задействованных в исследовании. До сих пор мы говорили об использовании двух форм тестирования в двух разных администрациях. Этот план исследования находится в правом нижнем углу таблицы 5.2, и он дает нам оценку эквивалентности (для двух разных форм теста) и стабильности (для двух разных применений теста). Этот план исследования потенциально может охватить большинство источников ошибок измерения и, таким образом, может дать самую низкую оценку надежности из-за двух задействованных факторов.Чем больше времени проходит между администрациями и чем больше различаются две тестовые формы по своему содержанию и другим функциям, тем больше ошибок мы можем ожидать. С другой стороны, по мере того, как наши две тестовые формы применяются ближе по времени, мы перемещаемся из нижнего правого угла в верхний правый угол таблицы 5.2, и наша оценка надежности отражает меньшую погрешность измерения, вносимую с течением времени. Нам остается оценить эквивалентность двух форм.
Этот план исследования потенциально может охватить большинство источников ошибок измерения и, таким образом, может дать самую низкую оценку надежности из-за двух задействованных факторов.Чем больше времени проходит между администрациями и чем больше различаются две тестовые формы по своему содержанию и другим функциям, тем больше ошибок мы можем ожидать. С другой стороны, по мере того, как наши две тестовые формы применяются ближе по времени, мы перемещаемся из нижнего правого угла в верхний правый угол таблицы 5.2, и наша оценка надежности отражает меньшую погрешность измерения, вносимую с течением времени. Нам остается оценить эквивалентность двух форм.
По мере того, как наши тестовые формы становятся все более и более эквивалентными, мы в конечном итоге получаем ту же тестовую форму и переходим к первому столбцу в таблице 5.2, где оценивается один из двух типов надежности. Во-первых, если мы проведем один и тот же тест дважды с прохождением времени между введениями, мы сможем оценить стабильность наших измерений во времени. Учитывая, что один и тот же тест проводится дважды, любая ошибка измерения будет связана с течением времени, а не с различиями между тестовыми формами. Во-вторых, если мы проведем один тест только один раз, у нас больше не будет оценки стабильности, а также оценки надежности, основанной на корреляции.Вместо этого у нас есть оценка того, что называется внутренней согласованностью измерения. Это основано на отношениях между самими тестовыми заданиями, которые мы рассматриваем как миниатюрные альтернативные формы теста. На итоговую оценку надежности влияет ошибка, которая возникает из-за того, что сами статьи являются нестабильными оценками интересующей конструкции.
Учитывая, что один и тот же тест проводится дважды, любая ошибка измерения будет связана с течением времени, а не с различиями между тестовыми формами. Во-вторых, если мы проведем один тест только один раз, у нас больше не будет оценки стабильности, а также оценки надежности, основанной на корреляции.Вместо этого у нас есть оценка того, что называется внутренней согласованностью измерения. Это основано на отношениях между самими тестовыми заданиями, которые мы рассматриваем как миниатюрные альтернативные формы теста. На итоговую оценку надежности влияет ошибка, которая возникает из-за того, что сами статьи являются нестабильными оценками интересующей конструкции.
| 1 случай | Внутренняя согласованность | Эквивалентность |
| 2 случая | Стабильность | Эквивалентность и стабильность |
Надежность внутренней согласованности оценивается с использованием либо коэффициента альфа, либо надежности с разделением половин. Все остальные ячейки в таблице 5.2 содержат оценки надежности, основанные на коэффициентах корреляции.
Все остальные ячейки в таблице 5.2 содержат оценки надежности, основанные на коэффициентах корреляции.
Таблица 5.2 содержит четыре наиболее часто используемых плана исследования надежности. Существуют и другие варианты, в том числе образцы, основанные на более чем двух формах или более чем двух случаях, а также конструкции с оценками экспертов, обсуждаемые ниже.
Надежность Interrater
Это было похоже на то, как трех кошек задушили в переулке.
- Саймон Коуэлл, унижающий певца на American Idol
Надежность Interrater можно рассматривать как особый пример надежности, когда несоответствия связаны не с различиями в формах тестирования, тестовых заданиях или административных случаях, а с самим процессом выставления оценок, в котором люди или, в некоторых случаях, компьютеры участвуют в качестве оценщиков.Оценка с помощью рейтеров часто включает в себя некоторую форму оценки исполнения, например, выступление на сцене в рамках конкурса певцов. Оценка и оценка такого действия рейтерами вносят дополнительную ошибку в процесс измерения. Надежность Interrater позволяет нам изучить негативное влияние этой ошибки на наши результаты.
Оценка и оценка такого действия рейтерами вносят дополнительную ошибку в процесс измерения. Надежность Interrater позволяет нам изучить негативное влияние этой ошибки на наши результаты.
Обратите внимание, что ошибка рейтера - еще один фактор или аспект в процессе измерения. Поскольку это еще один аспект измерения, оценщики могут вносить ошибки, выходящие за рамки ошибок, возникающих из-за выборки элементов, различий в тестовых формах или прохождения времени между администрациями.Это делается явным образом в рамках теории обобщаемости, обсуждаемой ниже. Сначала вводятся более простые методы оценки надежности между экспертами.
Соглашение о доле
Доля согласия - это простейшая мера надежности между экспертами. Он рассчитывается как общее количество совпадений набора оценок, деленное на общее количество оцененных единиц наблюдения. Сильные стороны пропорционального согласования заключаются в том, что его легко вычислить и использовать с любым типом дискретной шкалы . Основным недостатком является то, что он не учитывает случайное совпадение рейтингов и использует только номинальную информацию по шкале, то есть любое упорядочение значений игнорируется.
Основным недостатком является то, что он не учитывает случайное совпадение рейтингов и использует только номинальную информацию по шкале, то есть любое упорядочение значений игнорируется.
Чтобы увидеть влияние случая, давайте смоделируем оценки двух судей, где оценки полностью случайны, как если бы оценки 0 и 1 выставлялись в соответствии с подбрасыванием монеты. Предположим, что 0 - решка, а 1 - решка. В этом случае мы могли бы ожидать, что два оценщика согласятся определенную часть времени случайно.Таблица () Функция создает перекрестную таблицу частот, также известную как перекрестная таблица. Частоты согласия находятся в диагональных ячейках, сверху слева направо, а частоты несогласия обнаруживаются повсюду.
# Имитация случайного подбрасывания монеты для двух оценщиков
# runif () генерирует случайные числа из формы
# распределение
flip1 <- круглый (runif (30))
flip2 <- круглый (runif (30))
таблица (flip1, flip2)
## flip2
## flip1 0 1
## 0 5 8
## 1 9 8 Давайте найдем соотношение пропорций для смоделированных данных подбрасывания монеты. Вопрос, на который мы отвечаем, заключается в следующем: как часто подбрасывания монеты имели одинаковую ценность, 0 или 1, для обоих оценщиков в течение 30 бросков? Перекрестная таблица показывает это согласие в первой строке и первом столбце, где оценщики перевернули «решку» по 5 раз, а во второй строке и втором столбце - оба оценщика перевернули «решку» по 8 раз. Мы можем сложить их, чтобы получить 13, и разделить на \ (n = 30 \), чтобы получить процентное согласие.
Вопрос, на который мы отвечаем, заключается в следующем: как часто подбрасывания монеты имели одинаковую ценность, 0 или 1, для обоих оценщиков в течение 30 бросков? Перекрестная таблица показывает это согласие в первой строке и первом столбце, где оценщики перевернули «решку» по 5 раз, а во второй строке и втором столбце - оба оценщика перевернули «решку» по 8 раз. Мы можем сложить их, чтобы получить 13, и разделить на \ (n = 30 \), чтобы получить процентное согласие.
Данные для следующих нескольких примеров были смоделированы для представления оценок, выставленных двумя оценщиками с определенной корреляцией, то есть с определенной надежностью.Таким образом, согласие здесь не случайно. В популяции оценки этих оценщиков коррелировали на уровне 0,90. Шкала оценок варьировалась от 0 до 6 баллов, со средними значениями 4 и 3 балла для экспертов 1 и 2 и стандартное отклонение 1,5 для обоих. Мы будем называть их оценками за эссе, как и оценки за эссе в разделе аналитического письма GRE. Оценки также были разделены на гипотетические 3 балла, что приводило к оценке либо «Неудача», либо «Пройдено».
Оценки также были разделены на гипотетические 3 балла, что приводило к оценке либо «Неудача», либо «Пройдено».
# Имитация оценок за эссе от двух оценщиков с населением
# корреляция 0.90, и немного другие средние баллы,
# с диапазоном баллов от 0 до 6
# Обратите внимание, что заглавная буква T является аббревиатурой от TRUE
эссе <- rsim (100, rho = .9, meanx = 4, meany = 3,
sdx = 1.5, sdy = 1.5, to.data.frame = T)
colnames (эссе) <- c ("r1", "r2")
эссе <- round (setrange (essays, to = c (0, 6)))
# Используйте отсечку больше или равную 3, чтобы определить
# оценок "сдано" или "не сдано"
# ifelse () принимает вектор ИСТИНА и ЛОЖЬ в качестве своего первого
# аргумент, и здесь возвращается "Pass" для TRUE и "Fail"
# для FALSE
эссе $ f1 <- factor (ifelse (essays $ r1> = 3, "Pass",
"Неудача"))
эссе $ f2 <- factor (ifelse (essays $ r2> = 3, "Pass",
"Неудача"))
таблица (эссе $ f1, эссе $ f2)
##
## Fail Pass
## Ошибка 19 0
## Пройти 27 54 Верхняя левая ячейка в приведенных выше выходных данных table () показывает, что для 19 человек оба оценщика дали «Неудачно». В нижней правой ячейке оба оценщика дали «Пройдено» 54 раза. Вместе эти две суммы представляют собой совпадение рейтингов 73. В других ячейках таблицы содержатся разногласия, где один оценщик сказал «Пройдено», а другой сказал «Неудачно». Разногласия случались 27 раз. Основываясь на этих итогах, каково соотношение между оценками «прошел / не прошел»?
В нижней правой ячейке оба оценщика дали «Пройдено» 54 раза. Вместе эти две суммы представляют собой совпадение рейтингов 73. В других ячейках таблицы содержатся разногласия, где один оценщик сказал «Пройдено», а другой сказал «Неудачно». Разногласия случались 27 раз. Основываясь на этих итогах, каково соотношение между оценками «прошел / не прошел»?
Таблица 5.3 показывает полную перекрестную таблицу необработанных оценок от каждого оценщика, с оценками от оценщика 1 ( эссе $ r1 ) в строках и оценщика 2 ( эссе $ r2 ) в столбцах.Группировка оценок по диагонали от верхнего левого угла до нижнего правого угла показывает тенденцию к совпадению оценок.
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| 2 | 5 | 8 | 1 | 0 | 0 | 0 | 0 |
| 3 | 0 | 6 | 11 | 2 | 1 | 0 | 0 |
| 4 | 0 | 0 | 9 | 9 | 10 | 0 | 0 |
| 5 | 0 | 0 | 1 | 4 | 6 | 3 | 1 |
| 6 | 0 | 0 | 0 | 2 | 3 | 3 | 10 |
Согласование пропорций для полной шкалы оценок, как показано в таблице 5. 3, можно рассчитать путем суммирования частот совпадений в диагональных элементах таблицы и деления на общее количество людей.
3, можно рассчитать путем суммирования частот совпадений в диагональных элементах таблицы и деления на общее количество людей.
# Вытяните диагональные элементы из кросс-таблицы с помощью
# diag (), суммируйте их и разделите на количество людей
сумма (diag (таблица (эссе $ r1, эссе $ r2))) / nrow (эссе)
## [1] 0,29 Наконец, давайте рассмотрим влияние случайного соглашения между одним из гипотетических людей-оценщиков и обезьяной, которая случайным образом применяет рейтинги, независимо от демонстрируемой производительности, как при подбрасывании монеты.
# Произвольная выборка из вектора c ("Pass", "Fail"),
# количество (эссе) раз, с заменой
# Без замены у нас было бы всего 2 значения для выборки
# из
обезьяна <- образец (c («Пройден», «Не сдан»), nrow (эссе),
replace = TRUE)
стол (эссе $ f1, обезьяна)
## обезьяна
## Fail Pass
## Ошибка 10 9
## Пройти 38 43 Результаты показывают, что гипотетический оценщик соглашается с обезьяной в 53 процентах случаев. Поскольку мы знаем, что оценки обезьяны были полностью случайными, мы знаем, что это соотношение пропорций полностью случайно.
Поскольку мы знаем, что оценки обезьяны были полностью случайными, мы знаем, что это соотношение пропорций полностью случайно.
Соглашение Каппа
Согласование пропорций полезно, но поскольку оно не учитывает случайного совпадения, его не следует использовать в качестве единственной меры согласованности между экспертами. Соглашение Каппа - это просто скорректированная форма пропорционального соглашения, в которой учитывается случайное соглашение.
Уравнение (5.9) содержит формулу для расчета каппа для двух оценщиков.
\ [\ begin {уравнение}
\ kappa = \ frac {P_o - P_c} {1 - P_c}
\ tag {5.9}
\ end {Equation} \]
Чтобы получить каппа, мы сначала вычисляем долю согласия, \ (P_o \), как мы это делали с согласованием пропорций.Это рассчитывается как общая сумма согласия, деленная на общее количество людей, которым проводится оценка. Затем мы вычисляем случайное совпадение, \ (P_c \), которое включает в себя умножение пропорций строки и столбца (итоговые значения строк и столбцов, деленные на общую сумму) из кросс-таблицы, а затем суммирование результата, как показано в уравнении (5. 10).
10).
\ [\ begin {уравнение}
P_c = P_ {первая строка} P_ {первая колонка} + P_ {следующая строка} P_ {следующая колонка} + \ точки + P_ {последняя строка} P_ {последняя колонка}
\ tag {5.10}
\ end {Equation} \]
Нет необходимости фиксировать уравнения (5.9) и (5.10) в память. Вместо этого они включены здесь, чтобы помочь вам понять, что каппа включает удаление случайного согласия из наблюдаемого соглашения, а затем деление этого наблюдаемого неслучайного соглашения на общее возможное неслучайное соглашение, то есть \ (1 - P_c \) .
Знаменатель уравнения каппа содержит максимально возможное совпадение, не зависящее от случая, а числитель - фактическое наблюдаемое совпадение, не зависящее от случая. Итак, максимально возможная каппа равна 1,0. Теоретически мы никогда не должны достигать меньшего согласия, чем ожидалось случайно, а это значит, что каппа никогда не должна быть отрицательной.Технически возможно, чтобы каппа была ниже 0. Когда каппа ниже 0, это означает, что наше наблюдаемое согласие ниже того, что мы ожидали из-за случайности. Каппа также не должна быть больше, чем согласованная пропорция. В данных примера соотношение пропорций уменьшилось с 0,29 до 0,159 для каппа.
Каппа также не должна быть больше, чем согласованная пропорция. В данных примера соотношение пропорций уменьшилось с 0,29 до 0,159 для каппа.
Также доступна взвешенная версия индекса каппа. Взвешенная каппа позволяет снизить негативное влияние частичных разногласий по сравнению с более серьезными разногласиями в оценках, принимая во внимание порядковый характер шкалы оценок.Например, в таблице 5.3 обратите внимание, что только диагональные элементы кросс-таблицы измеряют полное соответствие в баллах, а все остальные элементы измеряют несогласованность, даже близкие друг к другу, такие как 2 и 3. С взвешенной каппа мы можем придать меньший вес. этим меньшим разногласиям и большему весу большим разногласиям, таким как баллы 0 и 6 в нижнем левом и верхнем правом углу таблицы. Это взвешивание дает нам более высокую оценку согласия.
Здесь мы используем функцию astudy () из epmr для вычисления пропорций, каппа и взвешенных каппа индексов.Взвешенная каппа дает нам наивысшую оценку согласия. Обратитесь к документации для
Обратитесь к документации для astudy () , чтобы узнать, как рассчитываются веса.
# Используйте функцию astudy () из epmr, чтобы измерить согласованность
учеба (эссе [, 1: 2])
## согласен kappa wkappa
## 0,20 0,1586681 0,4787490
Корреляция Пирсона
Коэффициент корреляции Пирсона, представленный выше для надежности CTT, улучшает показатели согласованности за счет учета порядкового характера рейтингов без необходимости явного взвешивания.Корреляция говорит нам, насколько последовательно оценщики ранжируют людей. Порядок ранжирования, который ближе к согласованию, автоматически получает больший вес при определении общей согласованности оценок.
Основным ограничением коэффициента корреляции является то, что он игнорирует систематических различий в рейтингах, когда сосредотачивается на их порядках ранжирования. Это ограничение связано с тем фактом, что корреляции не учитывают линейные преобразования шкал оценок. Мы можем изменить среднее значение или стандартное отклонение одной или обеих коррелируемых переменных и получить тот же результат. Таким образом, если два оценщика дают последовательно разные оценки, например, если один оценщик в целом более снисходителен, коэффициент корреляции все еще может быть высоким до тех пор, пока порядок ранжирования людей не меняется.
Мы можем изменить среднее значение или стандартное отклонение одной или обеих коррелируемых переменных и получить тот же результат. Таким образом, если два оценщика дают последовательно разные оценки, например, если один оценщик в целом более снисходителен, коэффициент корреляции все еще может быть высоким до тех пор, пока порядок ранжирования людей не меняется.
Это ограничение очевидно в наших смоделированных оценках эссе, где оценщик 2 дал в среднем более низкие баллы, чем оценщик 1. Если мы вычтем 1 балл из каждой оценки оценщика 2, оценки разных оценщиков будут более похожими, как показано на рисунке 5.4, но мы все равно получаем ту же межэкспертную надежность.
# Определенные изменения в описательной статистике, например добавление
# константы не повлияют на корреляции
cor (эссе $ r1, эссе $ r2)
## [1] 0,8536149
dstudy (эссе [, 1: 2])
##
## Описательное исследование
##
## средняя медиана sd skew kurt min max n na
## r1 3,86 4 1,49 -0,270 2,48 0 6 100 0
## r2 2,88 3 1,72 0,242 2,15 0 6 100 0
cor (эссе $ r1, эссе $ r2 + 1)
## [1] 0,8536149 Систематическая разница в баллах может быть визуализирована путем последовательного вертикального или горизонтального сдвига точек на диаграмме разброса. На рис. 5.4 показано, что по мере того, как оценки для оценщика 2 смещаются выше, они больше соответствуют оценщику 1 в абсолютном смысле, несмотря на то, что лежащая в основе линейная взаимосвязь остается неизменной.
На рис. 5.4 показано, что по мере того, как оценки для оценщика 2 смещаются выше, они больше соответствуют оценщику 1 в абсолютном смысле, несмотря на то, что лежащая в основе линейная взаимосвязь остается неизменной.
# Сравнение графиков разброса
ggplot (эссе, aes (r1, r2)) +
geom_point (position = position_jitter (w = .1, h = .1)) +
geom_abline (col = "синий")
ggplot (эссе, aes (r1, r2 + 1)) +
geom_point (position = position_jitter (w = .1, h = .1)) +
geom_abline (col = "blue") Рисунок 5.4: графики разброса смоделированных оценок за эссе с систематической разницей около 0,5 балла.
Это проблема, что корреляция игнорирует систематические различия в баллах? Можете ли вы вспомнить какие-нибудь жизненные ситуации, в которых это не дало бы повода для беспокойства? Простой пример - присуждение стипендий или других видов наград или признаний. В этих случаях последовательное ранжирование является ключевым, а систематические различия менее важны, поскольку цель ранжирования - выявить лучшего кандидата. Абсолютной шкалы оценки предметов не существует. Вместо этого они оцениваются по сравнению друг с другом. В результате систематическая разница в рейтингах технически не имеет значения.
Абсолютной шкалы оценки предметов не существует. Вместо этого они оцениваются по сравнению друг с другом. В результате систематическая разница в рейтингах технически не имеет значения.
Теория обобщаемости
Теория обобщаемости (G) устраняет ограничения других показателей надежности, предоставляя структуру, в которой могут быть учтены систематические различия в баллах, а также взаимодействия, которые могут иметь место в более сложных проектах исследования надежности.Основа теории G основана на модели CTT.
Здесь дается краткое введение в теорию G с обсуждением некоторых ключевых соображений при разработке исследования G и интерпретации результатов. Ресурсы для получения дополнительных сведений включают вводную дидактическую статью Бреннана (1992) и учебники Шавелсона и Уэбба (1991) и Бреннана (2001).
Модель
Вспомните из уравнения (5.1), что в CTT наблюдаемая общая оценка \ (X \) разделяется на простую сумму истинной оценки \ (T \) и ошибки \ (E \). 2_X \).
2_X \).
В отличие от CTT, теория G разбивает достоверную изменчивость на более мелкие части на основе аспектов в дизайне исследования. Каждый аспект - это особенность нашего сбора данных, которая, как мы ожидаем, приведет к поддающейся оценке изменчивости в нашей общей оценке \ (X \). В CTT есть только один аспект - люди. Но теория G также позволяет нам учитывать достоверную изменчивость, в том числе из-за оценщиков. В результате уравнения (5.1) и (5.11) расширяются или обобщаются в (5.13) и (5.2_P \). Затем в знаменателе выделяется достоверная дисперсия, обусловленная оценщиками, и технически рассматривается как систематический компонент наших оценок ошибок. Обратите внимание, что, если в создании наблюдаемых оценок нет экспертов, \ (R \) исчезает, \ (T \) полностью фиксируется \ (P \), а уравнение (5.15) становится (5.3).
Коэффициенты обобщаемости можно оценить различными способами. Пакет epmr включает функции для оценки нескольких различных типов \ (g \) с использованием многоуровневого моделирования с помощью пакета lme4 (Bates et al. 2015).
2015).
Приложения модели
Если все эти уравнения вызывают у вас острые взгляды, вам следует вернуться к вопросу, который мы задавали ранее: почему человек может по-разному набирать баллы в тесте от одной администрации к другой? Ответ: из-за различий в людях, из-за различий в процессе оценки и из-за ошибки. Цель теории G - сравнить влияние этих различных источников на вариативность оценок.
Определение \ (g \) в уравнении (5.15) представляет собой простой пример того, как мы можем оценить надежность человека по дизайну исследования. Поскольку он разбивает дисперсию оценок на несколько надежных компонентов, \ (g \) также можно использовать в более сложных схемах, где мы ожидаем, что какой-то другой аспект сбора данных приведет к надежной изменчивости оценок. Например, если мы проводим два эссе в двух случаях, и в каждом случае одни и те же два эксперта выставляют оценку по каждому предмету, мы получаем полностью пересекающийся дизайн с тремя аспектами: оцениватели, задачи (т. е., очерки) и поводах (например, Goodwin 2001). При разработке или оценке теста мы должны учитывать дизайн исследования, используемый для оценки надежности, а также то, используются ли соответствующие аспекты.
е., очерки) и поводах (например, Goodwin 2001). При разработке или оценке теста мы должны учитывать дизайн исследования, используемый для оценки надежности, а также то, используются ли соответствующие аспекты.
Помимо выбора аспектов в нашем исследовании надежности, есть еще три ключевых момента при оценке надежности с помощью \ (g \). Во-первых, нужно ли нам делать абсолютных или относительных интерпретаций баллов. Интерпретации абсолютных оценок учитывают систематические различия в оценках, тогда как интерпретации относительных оценок - нет.Как упоминалось выше, коэффициент корреляции учитывает только относительную согласованность оценок, и на него не влияют систематические, то есть абсолютные различия в оценках. Используя \ (g \), мы можем решить скорректировать нашу оценку надежности в сторону понижения, чтобы учесть эти различия. Оценку абсолютной надежности из теории G иногда называют коэффициентом надежности \ (d \).
Второе соображение - это количество уровней для каждого аспекта в нашем исследовании надежности, которые будут присутствовать при оперативном администрировании теста. По умолчанию надежность на основе корреляции оценивается для одного уровня каждого аспекта. Когда мы сопоставляем баллы по двум формам теста, результатом является оценка надежности самого теста, а не комбинация двух форм теста. В рамках теории G расширение формулы Спирмена-Брауна может использоваться для прогнозирования увеличения или уменьшения \ (g \) на основе увеличения или уменьшения количества уровней для фасета. Когда Спирмен-Браун был введен в уравнение (5.5), мы учитывали изменения в длине теста, когда увеличение длины теста увеличивало надежность.Теперь мы также можем учитывать изменения в количестве оценщиков, или поводах, или любых аспектах нашего исследования. Эти прогнозы упоминаются в литературе по теории G как исследования принятия решений. Результирующие коэффициенты \ (g \) помечаются как , среднее значение , если для фасета задействовано более одного уровня, и для одного уровня, в противном случае.
По умолчанию надежность на основе корреляции оценивается для одного уровня каждого аспекта. Когда мы сопоставляем баллы по двум формам теста, результатом является оценка надежности самого теста, а не комбинация двух форм теста. В рамках теории G расширение формулы Спирмена-Брауна может использоваться для прогнозирования увеличения или уменьшения \ (g \) на основе увеличения или уменьшения количества уровней для фасета. Когда Спирмен-Браун был введен в уравнение (5.5), мы учитывали изменения в длине теста, когда увеличение длины теста увеличивало надежность.Теперь мы также можем учитывать изменения в количестве оценщиков, или поводах, или любых аспектах нашего исследования. Эти прогнозы упоминаются в литературе по теории G как исследования принятия решений. Результирующие коэффициенты \ (g \) помечаются как , среднее значение , если для фасета задействовано более одного уровня, и для одного уровня, в противном случае.
Третье соображение - это тип выборки, используемый для каждого аспекта в нашем исследовании, в результате чего получается либо случайных , либо фиксированных эффектов. Фасеты можно рассматривать либо как случайные выборки из теоретически бесконечной совокупности, либо как фиксированные, то есть не как выборки из какой-либо более широкой совокупности. До сих пор мы по умолчанию обрабатывали все аспекты как случайные эффекты. Люди в нашем исследовании надежности представляют более широкую популяцию людей, как и оценщики. Фиксированные эффекты будут подходить для фасетов с единицами или уровнями, которые будут использоваться последовательно и исключительно во всех операционных администрациях теста. Например, в плане исследования с двумя вопросами для сочинения, оцененными двумя экспертами, мы будем рассматривать вопросы для сочинения как фиксированные, если мы никогда не собираемся использовать другие вопросы, кроме этих двух.Наши вопросы не являются образцами из множества потенциальных вопросов для сочинения. Если вместо этого наши вопросы представляют собой просто два из многих возможных вопросов, которые можно было бы написать или выбрать, было бы более уместно рассматривать этот аспект в нашем исследовании как случайный эффект. Эффекты фиксации увеличивают надежность, поскольку ошибка, присущая случайной выборке, устраняется из \ (g \). Тогда указание случайных эффектов снизит надежность, поскольку дополнительная ошибка от случайной выборки объясняется как \ (g \).
Фасеты можно рассматривать либо как случайные выборки из теоретически бесконечной совокупности, либо как фиксированные, то есть не как выборки из какой-либо более широкой совокупности. До сих пор мы по умолчанию обрабатывали все аспекты как случайные эффекты. Люди в нашем исследовании надежности представляют более широкую популяцию людей, как и оценщики. Фиксированные эффекты будут подходить для фасетов с единицами или уровнями, которые будут использоваться последовательно и исключительно во всех операционных администрациях теста. Например, в плане исследования с двумя вопросами для сочинения, оцененными двумя экспертами, мы будем рассматривать вопросы для сочинения как фиксированные, если мы никогда не собираемся использовать другие вопросы, кроме этих двух.Наши вопросы не являются образцами из множества потенциальных вопросов для сочинения. Если вместо этого наши вопросы представляют собой просто два из многих возможных вопросов, которые можно было бы написать или выбрать, было бы более уместно рассматривать этот аспект в нашем исследовании как случайный эффект. Эффекты фиксации увеличивают надежность, поскольку ошибка, присущая случайной выборке, устраняется из \ (g \). Тогда указание случайных эффектов снизит надежность, поскольку дополнительная ошибка от случайной выборки объясняется как \ (g \).
Функция gstudy () в пакете epmr оценивает дисперсии и относительные, абсолютные, единичные и средние коэффициенты \ (g \) для проектов исследования надежности с несколькими аспектами, включая фиксированные и случайные эффекты. Здесь мы моделируем оценки за эссе для третьего оценщика в дополнение к двум другим из предыдущих примеров, и мы исследуем межэкспертную надежность этого гипотетического примера тестирования для всех трех оценщиков сразу. Без теории G корреляции или индексы согласия необходимо было бы вычислять для каждой пары оценщиков.
# Провести исследование по моделируемым баллам за эссе
эссе $ r3 <- rsim (100, rho = 0,9, x = эссе $ r2,
meany = 3,5, sdy = 1,25) $ y
эссе $ r3 <- round (setrange (essays $ r3, to = c (0, 6)))
gstudy (эссе [, c ("r1", "r2", "r3")])
##
## Исследование обобщаемости
##
## Вызов:
## gstudy.merMod (x = mer)
##
## Формула модели:
## оценка ~ 1 + (1 | человек) + (1 | эксперт)
##
## Надежность:
## g sem
## Относительное среднее 0,9368 0,3536
## Относительный одиночный 0,8316 0,6125
## Абсолютное среднее 0.8996 0,4546
## Абсолютный одиночный 0,7492 0,7874
##
## Компоненты отклонения:
## дисперсия n1 n2
## person 1.8520 100 1
## рейтер 0,2449 3 3
## остаток 0,3751 NA NA
##
## Решение №:
## человек оценщик
## 100 3 При задании объекта data.frame , такого как essays , gstudy () автоматически принимает дизайн с одним аспектом, состоящим из столбцов данных, где единицы наблюдения находятся в строках. И строки, и столбцы обрабатываются как случайные эффекты.Чтобы оценить фиксированные эффекты для одного или нескольких аспектов, вместо этого необходимо использовать интерфейс формулы для функции. Подробности см. В документации по gstudy () .
Наши смоделированные оценки трех эссе дают относительное среднее значение \ (g \) 0,937. Это интерпретируется как согласованность оценок, которую мы ожидаем при оперативном проведении этого теста, когда средний балл за эссе берется по трем оценщикам. Предполагается, что оценщики, выставляющие оценки, отбираются из совокупности оценщиков, и любые систематические различия в оценках между оценщиками игнорируются.Относительное единичное значение \ (g \) 0,832 интерпретируется как согласованность оценок, которую мы ожидали бы, если бы решили сократить процесс оценки до одного эксперта, а не всех трех. Предполагается, что этот единственный оценщик отбирается из совокупности, и систематические различия в оценках по-прежнему игнорируются. Абсолютное среднее значение \ (g \) 0,900 и абсолютное единичное значение \ (g \) 0,749 интерпретируются одинаково, но учитываются систематические различия в баллах, и, таким образом, оценки надежности ниже относительных.
Что такое надежность? | Simply Psychology
- Методы исследования
- Надежность
Что такое надежность?
Д-р Саул МакЛеод, опубликовано в 2013 г.
Термин «надежность» в психологическом исследовании относится к последовательности исследовательского исследования или измерительного теста.
Например, если человек взвешивается в течение дня, он ожидает увидеть подобное значение. Весы, которые измеряли вес каждый раз по-разному, были бы малопригодны.
Ту же аналогию можно применить к рулетке, которая измеряет дюймы каждый раз по-разному. Это не считается надежным.
Если результаты исследований постоянно тиражируются, они надежны. Для оценки степени надежности можно использовать коэффициент корреляции. Если тест надежен, он должен показать высокую положительную корреляцию.
Конечно, маловероятно, что одни и те же результаты будут получены каждый раз, поскольку участники и ситуации меняются, но сильная положительная корреляция между результатами одного и того же теста указывает на надежность.
Есть два типа надежности - внутренняя и внешняя.
- Внутренняя надежность оценивает согласованность результатов по элементам теста.
- Внешняя надежность относится к степени, в которой мера варьируется от одного использования к другому.
Оценка надежности
Метод разделения половин
Метод разделения половин оценивает внутреннюю согласованность теста, такого как психометрические тесты и анкеты.Там он измеряет степень, в которой все части теста в равной степени влияют на то, что измеряется.
Это делается путем сравнения результатов одной половины теста с результатами другой половины. Тест можно разделить пополам несколькими способами, например: первую половину и вторую половину, или четными и нечетными числами. Если две половины теста дают одинаковые результаты, это говорит о том, что тест имеет внутреннюю надежность.
Надежность теста можно повысить с помощью этого метода.Например, любые элементы в отдельных частях теста, которые имеют низкую корреляцию (например, r = 0,25), следует либо удалить, либо переписать.
Метод разделения половин - это быстрый и простой способ определения надежности. Однако это может быть эффективным только с большими анкетами, в которых все вопросы измеряют одну и ту же конструкцию. Это означает, что он не подходит для тестов, которые измеряют разные конструкции.
Например, Миннесотский многофазный опросник личности имеет подшкалы, измеряющие различные формы поведения, такие как депрессия, шизофрения, социальная интроверсия.Поэтому метод разделения половин не подходил для оценки надежности этого личностного теста.
Повторное тестирование
Метод повторного тестирования оценивает внешнюю согласованность теста. Примеры подходящих тестов включают анкеты и психометрические тесты. Он измеряет стабильность теста во времени.
Типичная оценка включает в себя предоставление участникам одного и того же теста в двух разных случаях. Если получены такие же или похожие результаты, устанавливается внешняя надежность.Недостатки метода повторного тестирования заключаются в том, что получение результатов занимает много времени.
Beck et al. (1996) изучали ответы 26 амбулаторных пациентов на два отдельных терапевтических сеанса с интервалом в одну неделю, они обнаружили корреляцию 0,93, что демонстрирует высокую надежность перечня депрессий при повторных тестах.
Это пример того, почему необходима надежность психологических исследований, если бы не надежность таких тестов, некоторым людям не удалось бы успешно диагностировать такие расстройства, как депрессия, и, следовательно, им не было бы назначено соответствующее лечение.
Время проведения теста важно; если продолжительность короткая, участники могут вспомнить информацию из первого теста, которая может исказить результаты.
В качестве альтернативы, если продолжительность слишком велика, вполне возможно, что участники могли измениться каким-либо важным образом, что также может повлиять на результаты.
Надежность между экспертами
Метод повторного тестирования оценивает внешнюю согласованность теста. Это относится к степени, в которой разные оценщики дают согласованные оценки одного и того же поведения.При проведении собеседований можно использовать межэкспертную надежность.
Обратите внимание, что это также можно назвать надежностью между наблюдателями, когда речь идет о наблюдательных исследованиях. Здесь исследователи независимо наблюдают за одним и тем же поведением (чтобы избежать предвзятости) и сравнивают свои данные. Если данные похожи, то они надежны.
Если оценки наблюдателей существенно не коррелируют, надежность можно повысить за счет:
- Обучить наблюдателей используемым методам наблюдения и убедиться, что все согласны с ними.
- Обеспечение ввода в действие категорий поведения. Значит, они определены объективно.
Например, если два исследователя наблюдают «агрессивное поведение» детей в яслях, они оба будут иметь собственное субъективное мнение о том, что собой представляет агрессия. В этом сценарии маловероятно, что они будут регистрировать такое же агрессивное поведение, и данные будут ненадежными.
Однако, если бы они операционализировали поведенческую категорию агрессии, это было бы более объективным и облегчило бы определение того, когда происходит конкретное поведение.
Например, в то время как «агрессивное поведение» является субъективным и не реализуемым, «подталкивание» является объективным и оперативным. Таким образом, исследователи могли просто подсчитать, сколько раз дети толкали друг друга за определенный промежуток времени.
Как ссылаться на эту статью:
Как ссылаться на эту статью:
McLeod, S.A. (2007). Что такое надежность? . Просто психология. www.simplypsychology.org/reliability.html
Ссылки на стили APA
Бек, А. Т., Стир, Р. А., и Браун, Г. К. (1996). Руководство по инвентаризации депрессии Бека Психологическая корпорация. Сан-Антонио , Техас.
Hathaway, S. R., & McKinley, J. C. (1943). Руководство по многофазной инвентаризации личности в Миннесоте . Нью-Йорк: Психологическая корпорация.
сообщить об этом объявлении
Что означает альфа Кронбаха?
Альфа Кронбаха - это мера внутренней согласованности, то есть того, насколько близко
связанный набор предметов как группа.Считается мерой
надежности шкалы. «Высокое» значение альфа
не означает, что мера одномерная. Если помимо измерения
внутренняя согласованность, вы хотите предоставить доказательства того, что рассматриваемая шкала
одномерные, можно проводить дополнительные анализы. Исследовательский фактор
Анализ - это один из методов проверки размерности. С технической точки зрения альфа Кронбаха не
статистический тест - это коэффициент надежности (или согласованности).
Альфа Кронбаха может быть написана
как функция количества тестовых заданий и средней взаимной корреляции
среди предметов.Ниже для концептуальных целей мы показываем формулу для
альфа Кронбаха:
$$ \ alpha = \ frac {N \ bar {c}} {\ bar {v} + (N-1) \ bar {c}} $$
Здесь $ N $ равно количеству элементов, $ \ bar {c} $ - средняя ковариация между элементами среди элементов и
$ \ bar {v} $ равняется средней дисперсии.
Из этой формулы видно, что, увеличивая количество элементов, вы увеличиваете альфа Кронбаха.
Кроме того, если средняя корреляция между элементами низкая, альфа будет низкой.По мере увеличения средней корреляции между элементами альфа Кронбаха также увеличивается (количество элементов остается постоянным).
Пример
Давайте рассмотрим пример того, как вычислить альфа Кронбаха с помощью SPSS и как проверить размерность
шкалы с помощью факторного анализа. В этом примере мы будем использовать набор данных, содержащий четыре тестовых элемента - q1 , q2 , q3 и q4 . Вы можете скачать набор данных, щелкнув https: // stats.idre.ucla.edu/wp-content/uploads/2016/02/alpha.sav.
Чтобы вычислить альфа Кронбаха для всех четырех элементов - q1, q2, q3, q4 - используйте команду надежности :
НАДЕЖНОСТЬ / ПЕРЕМЕННЫЕ = q1 q2 q3 q4.
Вот результат синтаксиса выше:
Альфа-коэффициент для четырех элементов равен 0,839, что позволяет предположить, что элементы
имеют относительно высокую внутреннюю консистенцию. (Примечание
что коэффициент надежности.70 или выше считается
«Приемлемо» в большинстве исследовательских ситуаций в области социальных наук.)
Ручной расчет Alpha
Кронбаха
В целях демонстрации, вот как вычислить результаты вручную. В SPSS вы можете получить ковариации, перейдя на страницу Анализировать - Коррелят - Двумерный . Затем переместите q1 , q2 , q3 и q4 в поле Variables и щелкните Options .В разделе Статистика проверьте Отклонения и ковариации между произведениями . Нажмите «Продолжить» и «ОК», чтобы получить результат.
Ниже вы увидите сокращенную версию вывода. Обратите внимание, что диагонали (выделены жирным шрифтом) - это дисперсии, а недиагонали - ковариации. Нам нужно только рассмотреть ковариации в нижнем левом треугольнике, потому что это симметричная матрица.
| кв. 1 | кв. 2 | кв. | кв. 4 | ||
| кв. 1 | Коварианс | 1.168 | .557 | , 574 | .673 |
| кв. 2 | Ковариация | .557 | 1,012 | . 690 | .720 |
| 3 квартал | Ковариация | . 574 | .690 | 1,169 | ,724 |
| кв. 4 | Ковариация | .673 | .720 | . 724 | 1,291 |
Напомним, что $ N = 4 $ равно количеству элементов, $ \ bar {c} $ - это средняя ковариация между элементами между элементами и
$ \ bar {v} $ равняется средней дисперсии. Используя информацию из приведенной выше таблицы, мы можем рассчитать каждый из этих компонентов следующим образом:
$$ \ bar {v} = (1,168 + 1,012 + 1,169 + 1,291) / 4 = 4.64/4 = 1,16. $$
$$ \ bar {c} = (0,557 + 0,574 + 0,690 + 0,673 + 0,720 + 0,724) / 6 = 3,938 / 6 = 0,656. $$
$$ \ alpha = \ frac {4 (0,656)} {(1,16) + (4-1) (0,656)} = 2,624 / 3,128 = 0,839. $$
Результаты соответствуют нашему SPSS, получившему альфа Кронбаха 0,839.
Проверка размерности
Помимо вычисления альфа-коэффициента надежности, мы могли бы также
хочу исследовать размерность шкалы. Мы можем использовать коэффициент
команда для этого:
ФАКТОР / ПЕРЕМЕННЫЕ q1 q2 q3 q4 / FORMAT SORT BLANK (.35).
Вот результат
из синтаксиса выше:
Глядя на таблицу, обозначенную как «Объяснение общей дисперсии», мы видим, что собственное значение для
первый множитель немного больше, чем собственное значение для следующего множителя (2.7
против 0,54).
Кроме того, на первый фактор приходится 67% общей дисперсии. Это говорит о том, что
предметы шкалы одномерны.
Для получения дополнительной информации
границ | Сравнение трех эмпирических оценок надежности компьютерного адаптивного тестирования (CAT) с использованием экзамена на получение медицинской лицензии
Введение
Ницевандер и Томассон (1999) применили методы Арифметика, Гармоника и неравенства Дженсена для маргинализации тестовой информации для оценки оценок надежности IRT в компьютеризированном адаптивном тестировании (CAT).Тем не менее, задания были взяты из банков заданий, содержащих в среднем 80 заданий на тест, что было больше, чем на практике, установленной CAT. Кроме того, во многих программах практического оценивания в CAT часто используются взаимозаменяемые три показателя надежности IRT ( арифметических, гармонических и неравенств Дженсена ). Таким образом, целью этого краткого отчета было сравнение трех методов вычисления маргинализации наблюдаемой стандартной ошибки (OSE), которая может быть выражена обратной функцией тестовой информации для оценки надежности CAT при различной продолжительности теста.θ) 2. Математическая форма трехпараметрической логистической модели (3PLM; Bock and Lieberman, 1970) записывается как:
Pij = ci + (1-ci) exp [1.7ai (θj-bi)] 1 + exp [1.7ai (θj-bi)], (1)
, где P ij - вероятность правильного ответа на вопрос i при заданном θ для испытуемого j , θ j - это скрытая способность для испытуемого j, b i i - параметр сложности элемента для элемента i, a i - параметр распознавания элемента для элемента i, c i - параметр псевдогадания для элемента i .2. (12)
Методы
Программа испытаний
Пул предметов был создан на основе экзаменов для техников скорой медицинской помощи (EMT), проведенных с 01.01.2013 по 01.09.2014. На основании анализа практики ЕМТ, 17 ~ 21% пунктов теста были назначены для дыхательных путей, дыхания и вентиляции (АРВ), 16 ~ 20% пунктов были назначены на кардиологию и реанимацию (CR), 19 ~ 23% пунктов были назначены к травмам (TRA) 27 ~ 31% были отнесены к содержанию акушерства и гинекологии (MOG), а 12% ~ 16% были отнесены к содержанию операций скорой помощи (OPS).Пул оперативных элементов ЕМТ состоял из элементов, которые ранее были откалиброваны с использованием данных бумажно-карандашных тестов, и новых элементов, которые были зарегистрированы как тестируемые в предыдущем CAT. Пул предметов насчитывает 1136 предметов. Среднее значение параметров сложности заданий для пула заданий составило 0,969. Алгоритм выбора элементов и процедура сбалансированного содержания, предложенные Кингсбери и Зара (1989), были применены к этому исследованию. Алгоритм CAT случайным образом выбирает область содержимого в течение первых 5 элементов, а затем область содержимого, которая больше всего отличается от целевого процента, выбирается следующей, чтобы соответствовать плану тестирования (Kingsbury and Zara, 1989).
Моделирование данных
Дихотомическая модель IRT (Бок и Либерман, 1970) применялась для генерации ответов по заданию с тремя популяциями испытуемых [N (0,1), N (1,1) и N (2,1)]. Параметры a были сгенерированы из среднего значения 1,0 и стандартного отклонения 0,2 с D = 1,7, а параметр b был взят из пула элементов в условиях 2PLM, а параметр c был установлен на 0,25 до оцените условия 3PLM. Чтобы сгенерировать ответы для каждого теста, вероятности на основе модели IRT сравнивались со случайными числами из равномерного распределения, чтобы получить ответы на вопросы для каждого экзаменуемого.Если основанная на модели вероятность была больше случайного числа, ответ на этот элемент записывался как правильный (1). В противном случае ответ элемента был записан как неправильный (0). Этот процесс повторялся для каждого задания и испытуемого, чтобы получить полную матрицу ответов по каждому заданию. Всего было сгенерировано 1000 испытуемых для каждого пула с истинными θs после N (0,1), N (1,1) и N (2,1) с использованием D = 1,7. На рисунке 1A условие описывает модель 2PL с θs после N (0,1), (рисунок 1B) условие описывает модель 2PL с θs после N (1,1), (рисунок 1C) условие представляет модель 2PL с θs после N (2, 1) и (рисунок 1D) условие разработано для модели 3PL с θs после N (0,1).θ) 2). Три эмпирических достоверности CAT были получены с использованием среднего арифметического , среднего гармонического и неравенства Дженсена соответственно. Оценки способностей рассчитывались с использованием байесовской процедуры до тех пор, пока хотя бы на один вопрос не был дан правильный ответ, а на один вопрос не был дан неправильный ответ. На этом этапе оценки возможностей были рассчитаны с использованием метода MLE. Процедура Ньютона-Рафсона определила максимум правдоподобия с использованием итерационной процедуры для оценки θ для метода MLE.. Все алгоритмы CAT для этого исследования были реализованы пакетом catR (Magis and Raiche, 2012) в программе R (R Development Core Team, 2008).
Рисунок 1 . Сравнение трех оценок надежности IRT с истинной надежностью для четырех различных пулов элементов. (A) 2PLM Группа средних возможностей, (B) 2PLM Группа высоких возможностей, (C) 2PLM Группа экстремально высоких возможностей, (D) 3PLM Группа средних возможностей.
Результаты
На рисунке 1 показана функция трех эмпирических достоверностей CAT при четырех различных условиях.32 предоставили более крупные оценки после администрирования более 30 элементов для 2PLM и 50 элементов для 3PLM (рисунки 1A, D), а три оценки надежности не отличались от истинной надежности более чем на 0,01, когда количество управляемых элементов превышало 30 шт. 32 переоценивает истинную надежность только в том случае, если вводилось более 50 заданий, в которых среднее значение способности популяции было равно нулю.так что это не гарантирует точных оценок надежности, когда количество управляемых элементов было меньше 40 (отличалось более чем на 0,02 от истинной надежности). Хотя 3PLM хорошо соответствует данным, он не дает точной оценки способностей человека, потому что параметр c может увеличить дисперсию случайных ошибок для оценки испытуемых (Chiu and Camilli, 2013). В результате не рекомендуется сообщать о надежности CAT с помощью 3PLM, когда администрировалось небольшое количество элементов. По сравнению с исследованием Nicewander и Thomasson (1999), это исследование продемонстрировало, что три оценки надежности подходят для сообщения о надежности CAT независимо от распределения способностей в популяции и любых моделей IRT, если количество заданий в CAT составляло от 40 до 50.32 был ближе к истинной надежности, даже если было введено небольшое количество заданий, и его можно легко вычислить, используя одно значение тестовой информации при θ = 0 в этом исследовании. Обычно CAT считался эффективным и сравнивался с тестом фиксированной формы. Однако небольшое фиксированное количество элементов не было предложено в качестве критерия прекращения CAT для 2PLM, особенно для 3PLM, чтобы поддерживать высокие оценки надежности.
Как и любое другое исследование, это исследование имеет некоторые ограничения. В этом исследовании изучалась точность надежности CAT при определенных условиях медицинского лицензионного экзамена.Таким образом, существует ограничение на обобщение этого результата на другие условия тестирования. Будущие исследования потребуются для изучения точности надежности CAT при различных условиях, таких как различное распределение способностей и банки предметов с различными условиями параметров предмета.
Вклад автора
DS является первым автором, который концептуализирует и напишет этот краткий исследовательский отчет, а SJ является автором-корреспондентом, который руководит этим исследовательским проектом.
Финансирование
Работа поддержана исследовательским фондом Университета Халлим (HRF-201710-002).
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Список литературы
Бок Р. Д. и Либерман М. (1970). Подбор модели ответа для n дихотомически оцениваемых элементов. Психометрика 35, 179–197.
Google Scholar
Чиу, Т., и Камилли, Г. (2013).Комментарии к настройке 3PL IRT для угадывания. заявл. Psychol. Мера. 37, 76–86. DOI: 10.1177 / 0146621612459369
CrossRef Полный текст | Google Scholar
Crocker, L., and Algina, J. (1986). Введение в классическую и современную теорию тестирования. Нью-Йорк, Нью-Йорк: CBS College Publishing.
Google Scholar
Грин, Б. Ф., Бок, Р. Д., Хамфрис, Л. Г., Линн, Р. Л., и Рекказ, М. Д. (1984). Технические рекомендации по оценке компьютеризированных адаптивных тестов. J. Educ. Мера. 21, 347–360.
Google Scholar
Кингсбери, Г. Г., и Зара, А. Р. (1989). Процедуры выбора элементов для компьютеризированных адаптивных тестов. заявл. Мера. Educ. 2, 359–375.
Google Scholar
Лорд Ф. М. и Новик М. Р. (1968). статистических теорий о результатах психологических тестов . Ридинг, Массачусетс: Аддисон-Велси.
Google Scholar
Magis, D., and Raiche, G. (2012). Случайная генерация шаблонов ответов при компьютерном адаптивном тестировании с их пакетом catR. J. Статистика. Софтв. 48, 1–31. DOI: 10.18637 / jss.v048.i08
CrossRef Полный текст | Google Scholar
Ничевандер, В. А., и Томассон, Г. Л. (1999). Некоторые оценки надежности компьютерных адаптивных тестов. заявл. Psychol. Мера. 23, 239–247.
Google Scholar
Рао, К. Р. (1965). Линейный статистический вывод и его применение . Нью-Йорк, штат Нью-Йорк: Wiley.
Основная группа разработчиков
R (2008 г.